注意: 本文不涉及User Namespace,因为默认就是使用root用户运行,而且User Namespace和Mount Namespace的关系过于复杂: 程序员要远离本末倒置
- User Namespace: 只在Linux Kernel3.8开始才支持,因为在此之前,非root用户是无法创建User Namespace的。
User Namespace主要是隔离用户的用户组ID。也就是说,一个进程的User ID和Group ID在User Namespace内外可以是不同的。
比较常用的是,在宿主机上以一个非root用户运行创建一个User Namespace,然后在User Namespace里面却映射成root用户。
这意味着,这个进程在User Namespace里面有root权限,但是在User Namespace外面却没有root权限。
- 下面的代码,都是在内核版本3.13.0-xxx之下执行的。在将内核版本升级到这个版本的时候,需要修改些源代码,否则编译无法通过。
具体参考:https://git.kernel.org/pub/scm/linux/kernel/git/bluetooth/bluetooth-next.git/commit/?id=b075dd40c95d11c2c8690f6c4d6232fc0d9e7f56
问题:
- 容器本质上是一个被namespace和cgroup限制的一个特殊的进程,但是在使用docker容器的时候,我可以在里面使用jdk,netstat,ping等。
比如容器的初始进程是java进程,但是我可以进到进程容器里面执行各种命令,比如netstat和ping,这不就和容器是单进程的结论冲突了吗?
回复: 单进程意思不是只能运行一个进程,而是只有一个进程是可控的(控制指的是它们的回收和生命周期管理)。而其他进程是不受docker控制的,就像野孩子一样。
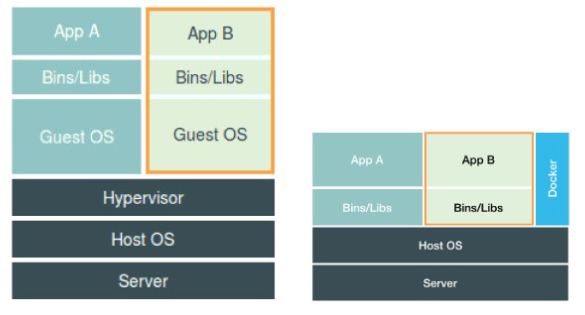
docker容器和操作系统的关系:
1. Linux Namespace介绍
当前linux一共实现了6种不同类型的Namespace。
| Namespace类型 |
系统调用参数 |
内核版本 |
| Mount Namespace |
CLONE_NEWNS |
2.4.19 |
| UTS Namespace |
CLONE_NEWUTS |
2.6.19 |
| IPC Namespace |
CLONE_NEWIPC |
2.6.19 |
| PID Namespace |
CLONE_NEWPID |
2.6.24 |
| Network Namespace |
CLONE_NEWNET |
2.6.29 |
| User Namespace(本文不涉及) |
CLONE_NEWUSER |
3.8 |
Namespace的API主要使用如下3个系统调用:
- clone()创建新进程。根据系统调用参数来判断哪些类型的Namespace被创建,而且它们的子进程也会被包含到这些Namespace中。
- unshare()将进程移出某个Namespace中
- setns()将进程加入到Namespace中。
UTS Namespace
UTS Namespace主要用来隔离nodename和domainname两个系统标识。在UTS Namespace里面,每个Namespace允许有自己的hostname。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
package main
import (
"os/exec"
"syscall"
"os"
"log"
)
func main() {
// 指定被fork出来的新进程内的初始命令,默认使用sh来执行。
cmd := exec.Command("sh")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
}
|
使用ps --forest -el命令可以查看到系统中进程之间的关系,如下:
1
2
3
4
5
6
|
4 S 0 1060 1 0 80 0 - 28231 poll_s ? 00:00:00 sshd
4 S 0 1565 1060 0 80 0 - 40253 poll_s ? 00:00:00 \_ sshd
4 S 0 1569 1565 0 80 0 - 29230 do_wai pts/0 00:00:00 | \_ bash
0 S 0 1657 1569 0 80 0 - 210933 futex_ pts/0 00:00:00 | \_ go
4 S 0 1692 1657 0 80 0 - 175793 do_wai pts/0 00:00:00 | \_ test
4 S 0 1696 1692 0 80 0 - 28886 n_tty_ pts/0 00:00:00 | \_ sh
|
然后,输出一下当前的PID:
验证一下父进程和子进程是否不在同一个UTS Namespace中,验证代码如下:
1
2
3
4
5
6
7
|
$ readlink /proc/1696/ns/uts
uts:[4026532179]
$ sh-4.2# readlink /proc/1692/ns/uts
uts:[4026531838]
$ hostname -b test-uts
$ hostname
test-uts
|
另外启动一个shell,在宿主机上运行hostname,看一下效果:
1
2
|
$ hostname
localhost.localdomain
|
可以看到,外部的hostname并没有被内部的修改所影响,由此可了解UTS Namespace的作用。
PID Namespace
PID Namespace是用来隔离进程ID的。同样一个进程在不同的PID Namespace里可以拥有不同的PID。
这样就可以理解,在docker container里面,使用ps -ef经常会发现,在容器内,前台运行的那个进程PID是1,但是在容器外,使用ps -ef会发现同样的进程却有不同的PID。
这就是PID Namespace做的事情。
给上面程序的Cloneflags添加syscall.CLONE_NEWPID标签,然后执行下面的操作:
首先在一个终端中执行:
1
2
3
|
$ go run test.go
sh-4.2# echo $$
1
|
接着再起一个终端,执行
1
2
3
4
5
6
7
|
$ ps --forest -el
4 S 0 1060 1 0 80 0 - 28231 poll_s ? 00:00:00 sshd
4 S 0 1565 1060 0 80 0 - 40253 poll_s ? 00:00:00 \_ sshd
4 S 0 1569 1565 0 80 0 - 29230 do_wai pts/0 00:00:00 | \_ bash
0 S 0 4032 1569 0 80 0 - 227381 futex_ pts/0 00:00:00 | \_ go
4 S 0 4067 4032 0 80 0 - 175793 do_wai pts/0 00:00:00 | \_ test
4 S 0 4071 4067 0 80 0 - 28917 n_tty_ pts/0 00:00:00 | \_ sh
|
可以发现,4071进程的PID被映射到Namespace里后PID为1。
这里还不能使用ps来查看,因为ps和top等命令会使用/proc内容。
Mount Namespace
Mount Namespace用来隔离各个进程看到的挂载点视图。在不同Namespace的进程里,看到的文件系统层次是不一样的。
在Mount Namespace中调用mount()和unmount()仅仅只会影响当前Namespace内的文件系统,而对全局的文件系统是没有影响的。
Mount Namespace是Linux第一个实现的Namespace类型,因此,它的系统调用参数是NEWNS。
当时人们貌似没有意识到,以后会有很多类型的Namespace加入Linux大家庭。
给上面程序的Cloneflags添加syscall.CLONE_NEWNS标签,然后执行下面的操作:
首先,运行代码,然后查看/proc的文件内容。(proc是一个文件系统,提供额外的机制,可以通过内核和内核模块将信息发送给进程)
1
2
3
4
5
6
7
8
9
10
11
12
13
|
$ go run test.go
sh-4.2#
sh-4.2# ls /proc
1 1386 19 27 296 37 405 411 46 6 625 691 731 cgroups execdomains kcore meminfo schedstat sysvipc
10 1388 2 273 297 38 406 412 47 605 65 692 742 cmdline fb keys misc scsi timer_list
101 14 20 28 298 380 407 413 48 617 653 696 8 consoles filesystems key-users modules self timer_stats
1060 1565 21 280 301 381 408 414 49 619 678 7 870 cpuinfo fs kmsg mounts slabinfo tty
1061 1569 22 29 303 3902 409 415 495 620 680 702 9 crypto interrupts kpagecount mtrr softirqs uptime
1063 16 23 291 335 3913 4099 4152 51 621 681 711 acpi devices iomem kpageflags net stat version
11 1700 24 292 35 392 410 4187 516 622 682 712 asound diskstats ioports loadavg pagetypeinfo swaps vmallocinfo
12 1704 25 293 36 393 4106 4191 52 623 683 713 buddyinfo dma irq locks partitions sys vmstat
13 18 26 294 3645 4 4107 4193 529 624 684 717 bus driver kallsyms mdstat sched_debug sysrq-trigger zoneinfo
sh-4.2#
|
Linux下的/proc文件系统是由内核提供的,它其实不是一个真正的文件系统,只包含了系统运行时的信息(比如系统内存、mount设备信息、一些硬件配置等),
它只存在于内存中,而不占用内存空间。它以文件系统的形式,为访问内核数据的操作提供接口。
当遍历这个目录的时候,会发现很多数字,这些都是为每个进程创建的空间,数字就是它们的PID。
/proc/N PID为N的进程信息
/proc/N/cmdline 进程启动命令
/proc/N/cwd 链接到进程当前工作目录
/proc/N/environ 进程环境变量列表
/proc/N/exe 链接到进程的执行命令文件
/proc/N/fd 包含进程相关的所有文件描述符
/proc/N/maps 与进程相关的内存映射信息
/proc/N/mem 指代进程持有的内存,不可读
/proc/N/root 链接到进程的根目录
/proc/N/stat 进程的状态
/proc/N/statm 进程使用的内存状态
/proc/N/status 进程状态信息,比stat/statm更具可读性
/proc/self 链接到当前正在运行的进程
可以发现/proc的内容,和宿主机的一模一样。下面,将/proc mount到我们自己的Namespace下面来。
1
2
3
4
5
6
7
8
9
10
11
|
sh-4.2# mount -t proc proc /proc
sh-4.2# ls /proc
1 bus crypto execdomains iomem keys loadavg modules partitions slabinfo sysrq-trigger uptime
4 cgroups devices fb ioports key-users locks mounts sched_debug softirqs sysvipc version
acpi cmdline diskstats filesystems irq kmsg mdstat mtrr schedstat stat timer_list vmallocinfo
asound consoles dma fs kallsyms kpagecount meminfo net scsi swaps timer_stats vmstat
buddyinfo cpuinfo driver interrupts kcore kpageflags misc pagetypeinfo self sys tty zoneinfo
sh-4.2# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 20:43 pts/0 00:00:00 sh
root 5 1 0 20:46 pts/0 00:00:00 ps -ef (问题: 为何比/proc里面记录的PID多了一个1)
|
但是这个时候,会发现宿主机上的/proc的内容和容器的一样了,而且容器中的PID为4的进程,在宿主机无法访问
1
2
3
4
5
6
7
|
ls /proc/
ls: 无法读取符号链接/proc/self: 没有那个文件或目录
1 cgroups devices fb ioports key-users locks mounts sched_debug softirqs sysvipc version
acpi cmdline diskstats filesystems irq kmsg mdstat mtrr schedstat stat timer_list vmallocinfo
asound consoles dma fs kallsyms kpagecount meminfo net scsi swaps timer_stats vmstat
buddyinfo cpuinfo driver interrupts kcore kpageflags misc pagetypeinfo self sys tty zoneinfo
bus crypto execdomains iomem keys loadavg modules partitions slabinfo sysrq-trigger uptime
|
通过查看容器的mountinfo,发现所有的挂在类型都是shared
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
sh-4.2# cat /proc/self/mountinfo
116 115 253:0 / / rw,relatime shared:1 - xfs /dev/mapper/centos-root rw,seclabel,attr2,inode64,noquota
117 116 0:5 / /dev rw,nosuid shared:2 - devtmpfs devtmpfs rw,seclabel,size=1928132k,nr_inodes=482033,mode=755
118 117 0:18 / /dev/shm rw,nosuid,nodev shared:3 - tmpfs tmpfs rw,seclabel
119 117 0:12 / /dev/pts rw,nosuid,noexec,relatime shared:4 - devpts devpts rw,seclabel,gid=5,mode=620,ptmxmode=000
120 117 0:35 / /dev/hugepages rw,relatime shared:24 - hugetlbfs hugetlbfs rw,seclabel
121 117 0:14 / /dev/mqueue rw,relatime shared:25 - mqueue mqueue rw,seclabel
122 116 0:3 / /proc rw,nosuid,nodev,noexec,relatime shared:5 - proc proc rw
123 122 0:36 / /proc/sys/fs/binfmt_misc rw,relatime shared:27 - autofs systemd-1 rw,fd=35,pgrp=0,timeout=0,minproto=5,maxproto=5,direct,pipe_ino=12572
124 116 0:17 / /sys rw,nosuid,nodev,noexec,relatime shared:6 - sysfs sysfs rw,seclabel
125 124 0:16 / /sys/kernel/security rw,nosuid,nodev,noexec,relatime shared:7 - securityfs securityfs rw
126 124 0:20 / /sys/fs/cgroup ro,nosuid,nodev,noexec shared:8 - tmpfs tmpfs ro,seclabel,mode=755
127 126 0:21 / /sys/fs/cgroup/systemd rw,nosuid,nodev,noexec,relatime shared:9 - cgroup cgroup rw,seclabel,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd
128 126 0:23 / /sys/fs/cgroup/hugetlb rw,nosuid,nodev,noexec,relatime shared:10 - cgroup cgroup rw,seclabel,hugetlb
129 126 0:24 / /sys/fs/cgroup/devices rw,nosuid,nodev,noexec,relatime shared:11 - cgroup cgroup rw,seclabel,devices
130 126 0:25 / /sys/fs/cgroup/blkio rw,nosuid,nodev,noexec,relatime shared:12 - cgroup cgroup rw,seclabel,blkio
131 126 0:26 / /sys/fs/cgroup/cpuset rw,nosuid,nodev,noexec,relatime shared:13 - cgroup cgroup rw,seclabel,cpuset
132 126 0:27 / /sys/fs/cgroup/pids rw,nosuid,nodev,noexec,relatime shared:14 - cgroup cgroup rw,seclabel,pids
133 126 0:28 / /sys/fs/cgroup/net_cls,net_prio rw,nosuid,nodev,noexec,relatime shared:15 - cgroup cgroup rw,seclabel,net_prio,net_cls
134 126 0:29 / /sys/fs/cgroup/cpu,cpuacct rw,nosuid,nodev,noexec,relatime shared:16 - cgroup cgroup rw,seclabel,cpuacct,cpu
135 126 0:30 / /sys/fs/cgroup/memory rw,nosuid,nodev,noexec,relatime shared:17 - cgroup cgroup rw,seclabel,memory
136 126 0:31 / /sys/fs/cgroup/freezer rw,nosuid,nodev,noexec,relatime shared:18 - cgroup cgroup rw,seclabel,freezer
137 126 0:32 / /sys/fs/cgroup/perf_event rw,nosuid,nodev,noexec,relatime shared:19 - cgroup cgroup rw,seclabel,perf_event
138 124 0:22 / /sys/fs/pstore rw,nosuid,nodev,noexec,relatime shared:20 - pstore pstore rw
139 124 0:33 / /sys/kernel/config rw,relatime shared:21 - configfs configfs rw
140 124 0:15 / /sys/fs/selinux rw,relatime shared:22 - selinuxfs selinuxfs rw
141 124 0:6 / /sys/kernel/debug rw,relatime shared:26 - debugfs debugfs rw
142 116 0:19 / /run rw,nosuid,nodev shared:23 - tmpfs tmpfs rw,seclabel,mode=755
143 142 0:38 / /run/user/0 rw,nosuid,nodev,relatime shared:136 - tmpfs tmpfs rw,seclabel,size=388028k,mode=700
144 116 8:1 / /boot rw,relatime shared:28 - xfs /dev/sda1 rw,seclabel,attr2,inode64,noquota
147 122 0:39 / /proc rw,relatime shared:96 - proc proc rw
|
所以对golang程序作出如下的修改:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
package main
import (
"os/exec"
"syscall"
"os"
"log"
)
func main() {
cmd := exec.Command("sh")
cmd.SysProcAttr = &syscall.SysProcAttr {
Cloneflags: syscall.CLONE_NEWUTS|syscall.CLONE_NEWIPC|syscall.CLONE_NEWPID|syscall.CLONE_NEWNS,
}
// 如果你的机器的根目录的挂载类型是shared,那必须先重新挂载根目录mount --make-rprivate
if err := syscall.Mount("","/","",syscall.MS_PRIVATE|syscall.MS_REC, ""); err != nil {
log.Fatal("make parent mount private error: %v", err)
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
// 运行父进程cmd
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
}
|
问题:上面的问题,虽然可以解决我们的问题,但是每次进入容器之后,都需要手动执行一遍mount -t proc proc /proc命令才行。
有没有什么办法可以解决这个问题呢?
1
2
3
4
5
6
|
sh-4.2# mount -t proc proc /proc
sh-4.2# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 22:59 pts/1 00:00:00 sh
root 3 1 0 23:00 pts/1 00:00:00 ps -ef
sh-4.2#
|
golang的syscall.Exec(argv0 string, argv []string, envv []string)函数的作用是:执行argv0所指定的可执行文件(会生成一个子进程),并覆盖父进程的镜像、数据和堆栈等信息,包括PID。syscall.Exec这个方法,其实最终调用了Kernel的int execve(const char *filename, char *const argv[], char *const envp[])这个系统函数。
所以可以把mount -t proc proc /proc操作放在子进程中完成,而Namespace的设置放在父进程中完成。
现在,还剩下最后一个问题,如何把子进程的可执行文件传递到父进程的Namespace中去呢?
只有一个办法,就是父进程和子进程共用同一个可执行文件,但是使用不同的Option来区分它们的功能。
实现代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
package main
import (
"os/exec"
"strings"
"syscall"
"os"
"log"
"flag"
)
var (
tty bool
cmd string
)
func main() {
if len(os.Args) < 3 {
println("parameter must greater than 2")
os.Exit(0)
}
cl := flag.NewFlagSet(os.Args[1], flag.ExitOnError)
// 设置option
cl.BoolVar(&tty, "it", false, "-it: use tty or not")
cl.Parse(os.Args[2:])
cmd := strings.Join(cl.Args(), " ")
println("cmd is : ", cmd)
switch os.Args[1] {
case "run":
println("run..............")
args := []string{"init", cmd}
cmd := exec.Command("/proc/self/exe", args...)
cmd.SysProcAttr = &syscall.SysProcAttr {
Cloneflags: syscall.CLONE_NEWUTS|syscall.CLONE_NEWIPC|syscall.CLONE_NEWPID|syscall.CLONE_NEWNS,
}
println("tty", tty)
if tty {
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
}
// 运行父进程cmd
if err := cmd.Start(); err != nil {
log.Fatal(err)
}
cmd.Wait()
os.Exit(-1)
case "init":
println("command is ", cmd)
// 如果你的机器的根目录的挂载类型是shared,那必须先重新挂载根目录mount --make-rprivate
if err := syscall.Mount("","/","",syscall.MS_PRIVATE|syscall.MS_REC, ""); err != nil {
log.Fatal("make parent mount private error: %v", err)
}
// MS_NOEXEC: 在文件系统中不允许运行其他程序
// MS_NOSUID: 在本系统中运行程序的时候,不允许set-user-ID或set-group-ID
// MS_NODEV: 这个参数是自从Linux2.4以来,所有mount的系统都会默认设定的参数
defaultMountFlags := syscall.MS_NOEXEC | syscall.MS_NOSUID | syscall.MS_NODEV
syscall.Mount("proc", "/proc", "proc", uintptr(defaultMountFlags), "")
argv := []string{cmd}
if err := syscall.Exec(cmd, argv, os.Environ()); err != nil {
println(err.Error())
}
default:
println("Usage: ./test run|init")
os.Exit(2)
}
}
|
Network Namespace
Network Namespce是用来隔离网络设备,IP地址端口等网络栈的Namespace。
Network Namespace可以让每个容器拥有自己独立的(虚拟的)网络设备,而且容器内的应用可以绑定到自己的端口,每个Namespace内的端口都不会互相冲突。
然后在宿主机上搭建网桥后,就能很方便地实现容器之间的通信。
在Mount Namespace程序的基础之上,给Cloneflags添加syscall.CLONE_NEWNET标识符,然后依次执行如下操作:
首先在宿主机上查看一下自己的网络设备,结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 08:00:27:a5:cd:44 brd ff:ff:ff:ff:ff:ff
inet 10.0.2.33/24 brd 10.0.2.255 scope global noprefixroute dynamic enp0s3
valid_lft 958sec preferred_lft 958sec
inet6 fe80::701a:5e4d:5852:e184/64 scope link noprefixroute
valid_lft forever preferred_lft forever
|
可以看到,宿主机上有lo, enp0s3这两个网络设备。然后运行程序去Network Namespace里面看看。
1
2
3
4
5
6
7
8
|
[root@localhost test]# ./test run -it /bin/sh
run..............
opt true
command is /bin/sh
sh-4.2# ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
sh-4.2#
|
可以看到,在Namespace里面只有一个本地环回的网络设备。这样就能断定Network Namespace与宿主机之间的网络是处于隔离状态了。
IPC Namespace
IPC Namespace用来隔离System V IPC和POSIX message queues。每一个IPC Namespace都有自己的System V IPC和POSIX message queue。
给上面程序的Cloneflags添加syscall.CLONE_NEWIPC标签,然后执行下面的操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# 查看现有的ipc message Queues
$ ipcs -q
--------- 消息队列 -----------
键 msqid 拥有者 权限 已用字节数 消息
# 下面创建一个message queue
ipcmk -Q
消息队列 id:0
# 然后再查看一下
ipcs -q
--------- 消息队列 -----------
键 msqid 拥有者 权限 已用字节数 消息
0x96e6ec45 0 root 644 0 0
|
这里,能够发现可以看到一个queue了。下面,使用另外一个shell去执行下面的命令:
1
2
3
4
5
|
[root@localhost test]# ./test run -it /bin/sh
sh-4.2# ipcs -q
--------- 消息队列 -----------
键 msqid 拥有者 权限 已用字节数 消息
|
通过以上实验,可以发现,在新创建的Namespace里,看不到宿主机上已经创建的message queue,说明IPC Namespace创建成功,IPC已经被隔离。
现在来介绍下,IPC Namespace是如何解决参数太长或者含有特殊字符的问题的:
在上面的程序中,在执行/bin/ls *的时候会报错:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
[root@localhost test]# ./test run -it /bin/ls
cmd is : /bin/ls
run..............
tty true
cmd is : /bin/ls
command is /bin/ls
test test.go
[root@localhost test]# ./test run -it /bin/ls *
cmd is : /bin/ls test test.go
run..............
tty true
cmd is : /bin/ls test test.go
command is /bin/ls test test.go
no such file or directory
|
当在Linux上创建两个进程时,进程之间的通信一般都会使用管道的机制。所谓管道,就是一个连接两个进程的通道,它是Linux支持IPC的其中一种方式。
一般来说,管道都是半双工的,一端进行写操作,另外一端进行读操作。常用的管道分为两种类型。一种类型是无名管道,它一般用于具有亲缘关系的进程之间;
另外一种是有名管道,或者叫FIFO管道,它是一种存在于文件系统的管道,可以被两个没有任何亲缘关系的进程进行访问。有名管道一般通过mkfifo()函数来创建。
从本质上来说,管道也是文件的一种,但是它和文件通信的区别在于,管道有一个固定大小的缓冲区,大小一般是4KB。
当管道被写满时,写进程就会被阻塞,直到有读进程把管道的内容读出来。同样的,当读进程从管道内拿数据的时候,如果这时管道的内容是空的,那么读进程同样会被阻塞,一直等到有写进程向管道内写数据。
上面演示的程序中,run子命令有一个缺陷,就是传递参数。在父进程(run)和子进程(init)之间传参,是通过调用命令时后面跟上参数,
也就是/proc/self/exe init args这种方式进行的,然后,在init进程内去解析这个参数,执行相应的命令。
但是,这有一个缺点,如果用户输入的参数很长,或者其中带有一些特殊的字符,那么这种方案就会失败了。
其实,runC实现的方案是通过匿名管道来实现父子进程之间通信的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
|
package main
import (
"os/exec"
"strings"
"syscall"
"os"
"log"
"flag"
"io/ioutil"
)
var (
tty bool
)
func NewPipe() (*os.File, *os.File, error) {
read, write, err := os.Pipe()
if err != nil {
return nil, nil, err
}
return read, write, nil
}
func readUserCommand() []string {
// uintptr(3)就是指index为3的文件描述符,也就是传递进来的管道的一端
// 第二参数表示文件的名字
pipe := os.NewFile(uintptr(3), "pipe")
msg, err := ioutil.ReadAll(pipe)
if err != nil {
println("init read pipe error: ", err.Error())
return nil
}
msgStr := string(msg)
return strings.Split(msgStr, " ")
}
func sendInitCommand(comArray []string, writePipe *os.File) {
command := strings.Join(comArray, " ")
println("command all is ", command)
writePipe.WriteString(command)
writePipe.Close()
}
func main() {
// 由于使用了管道,所以在调用init子命令的时候,是没有参数的
// 于是这里的3要改为2
if len(os.Args) < 2 {
println("parameter must greater than 1")
os.Exit(0)
}
cl := flag.NewFlagSet(os.Args[1], flag.ExitOnError)
// 设置option
cl.BoolVar(&tty, "it", false, "-it: use tty or not")
cl.Parse(os.Args[2:])
switch os.Args[1] {
case "run":
println("run..............")
readPipe, writePipe, err := NewPipe()
if err != nil {
println("New pipe error: ", err.Error())
os.Exit(-1)
}
cmd := exec.Command("/proc/self/exe", "init")
cmd.SysProcAttr = &syscall.SysProcAttr {
Cloneflags: syscall.CLONE_NEWUTS|syscall.CLONE_NEWIPC|syscall.CLONE_NEWPID|syscall.CLONE_NEWNS|syscall.CLONE_NEWNET|syscall.CLONE_NEWIPC,
}
println("tty", tty)
if tty {
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
}
// 注意,改动在这里,在这个地方传入管道文件读取端的句柄
// 管道是一个文件类型,肯定不能通过字符参数的方式进行传递,因此使用了command的cmd.ExtraFiles属性
// 这个属性的意思是会外带着这个文件句柄去创建子进程,可以使用命令`ll /proc/self/fd`来查看当前进程带着的所有文件描述符
// 由于,每个进程都会有三个默认的文件描述符,标准输入、标准输出、标准错误,所以这个外带的文件句柄就成了第四个。
cmd.ExtraFiles = []*os.File{readPipe}
// 运行父进程cmd
if err := cmd.Start(); err != nil {
log.Fatal(err)
}
// 发送用户命令
sendInitCommand(cl.Args(), writePipe)
cmd.Wait()
os.Exit(-1)
case "init":
cmdArray := readUserCommand()
if cmdArray == nil || len(cmdArray) == 0 {
println("Run container get user command error, cmdArray is nil")
os.Exit(-1)
}
println("command is ", strings.Join(cmdArray, " "))
// 如果你的机器的根目录的挂载类型是shared,那必须先重新挂载根目录mount --make-rprivate
if err := syscall.Mount("","/","",syscall.MS_PRIVATE|syscall.MS_REC, ""); err != nil {
log.Fatal("make parent mount private error: %v", err)
}
// MS_NOEXEC: 在文件系统中不允许运行其他程序
// MS_NOSUID: 在本系统中运行程序的时候,不允许set-user-ID或set-group-ID
// MS_NODEV: 这个参数是自从Linux2.4以来,所有mount的系统都会默认设定的参数
defaultMountFlags := syscall.MS_NOEXEC | syscall.MS_NOSUID | syscall.MS_NODEV
syscall.Mount("proc", "/proc", "proc", uintptr(defaultMountFlags), "")
// 改动,调用exec.LookPath, 可以在系统的PATH里面寻找命令的绝对路径
path, err := exec.LookPath(cmdArray[0])
if err != nil {
println("Exec loop path error : ", err.Error())
os.Exit(-1)
}
println("Find path: ", path)
if err := syscall.Exec(path, cmdArray[0:], os.Environ()); err != nil {
println(err.Error())
}
default:
println("Usage: ./test run|init")
os.Exit(2)
}
}
|
执行命令,会发现在执行ls *命令的时候,不再报错了:
1
2
3
4
5
6
7
|
[root@localhost test]# ./test run -it ls *
run..............
tty true
command all is ls test test.go
command is ls test test.go
Find path: /usr/bin/ls
test test.go
|
2. Linux Cgroups介绍
Linux Cgroups(Control Groups)提供了对一组进程及将来子进程的资源限制、控制和统计的能力,这些资源包括CPU、内存、存储、网络等。
Cgroups中的3个组件:
- cgroup是对进程分组管理的一种机制。(目录)
把一组进程(目录下的task文件)放到一个cgroup中,并给这个cgroup添加Linux subsystem的各种参数配置,
这样就把一组进程和一组subsystem的系统参数关联起来了。
- subsystem是一组资源控制的模块,一般包含如下几项(目录下的文件,除了task文件;不同subsystem类型,就会有不同的文件)
- blkio设备对块设备(比如硬盘)输入输出的访问控制
- cpu设置cgroup中进程的CPU被调度的策略
- cpuacct可以统计cgroup中进程的CPU占用
- cpuset在多核机器上设置cgroup中进程可以使用的CPU和内存(此处内存仅使用于NUMA架构)
- devices控制cgroup中进程对设备的访问
- freezer用于挂起(suspend)和恢复(resume)cgroup中的进程
- memory用于控制cgroup中进程的内存占用
net_cls用于将cgroup中进程产生的网络包分类,以便Linux的tc(traffic controller)可以根据分类区分出来自某个cgroup的包并做限流或流控。net_prio设置cgroup中进程产生的网络流量的优先级- ns这个subsystem比较特殊,它的作用是使cgroup中的进程在新的Namespace中fork新进程(NEWNS)时,创建出一个新的cgroup,这个cgroup包含新的Namespace中的进程。
如何看到当前的内核支持哪些subsystem呢?
可以安装cgroup的命令行工具(apt-get install cgroup-bin 或者 yum install -y libcgroup libcgroup-tools),然后通过lssubsys -a看到Kernel支持的subsystem
3. hierarchy的功能是把一组cgroup串成一个树状的结构,一个这样的树便是一个hierarchy,通过这种树状结构,Cgroups可以做到继承。
比如,系统对一组定时的任务进程通过cgroup1限制了CPU的使用率,然后其中有一个定时dump日志的进程还需要限制磁盘IO,
为了避免限制了磁盘IO之后影响到其他进程,就可以创建cgroup2,使其继承于cgroup1并限制磁盘的IO,
这样,cgroup2便继承了cgroup1中对CPU使用率的限制,并且增加了磁盘IO的限制而不影响到cgroup1中的其他进程。
三个组件相互的关系:
- 系统在创建了新的hierarchy之后,系统中所有的进程都会加入这个hierarchy的cgroup根节点,这个cgroup根节点是hierarchy默认创建的。
- important: 一个subsystem只能附加到一个hierarchy上面。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
|
# 查看系统当前支持哪些subsystem
$ lssubsys -a
# 查看系统当前有哪些hierarchy挂载
$ mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,freezer)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,pids)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,net_prio,net_cls)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,devices)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,blkio)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,perf_event)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpuacct,cpu)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,hugetlb)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,memory)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpuset)
# 创建一个hierarchy挂载点
$ mkdir cgroup-test
# 尝试创建一个已被默认的hierarchy包含的subsystem: cpu
$ mount -t cgroup -o cpu cpu cgroup-test
mount: cpu 已经挂载或 /root/go/src/github.com/test/cgroup-test 忙
# 所以,一个subsystem只能附加到一个hierarchy上面是正确的
# 我们现在创建一个不与任何subsystem关联的hierarchy(所以这个hierarchy没有任何作用)
$ mount -t cgroup -o none,name=cgroup-test cgroup-test ./cgroup-test
# 挂载后我们可以看到系统在这个目录下生成了一些默认文件
$ ls ./cgroup-test
cgroup.clone_children cgroup.event_control cgroup.procs cgroup.sane_behavior notify_on_release release_agent tasks
# cgroup.clone_children: cpuset这个subsystem会读取这个配置文件,如果这个值是1(默认是0),子cgroup才会继承父cgroup的cpuset的配置
# cgroup.procs: 是树中当前节点cgroup中的进程组ID,现在的位置是在根节点,这个文件中会有现在系统中所有进程组的ID。
# notify_on_release和release_agent会一起使用。notify_on_release标识当这个cgroup最后一个进程退出的时候是否执行了release_agent;release_agent则是一个路径,通常用作进程退出之后自动清理掉不再使用的cgroup。
# tasks标识该cgroup下面的进程ID,如果把一个进程ID写到tasks文件中,便会将相应的进程加入到这个cgroup中。
# 创建子cgroup "cgroup-1"
$ mkdir cgroup-1
# 创建子cgroup "cgroup-2"
$ mkdir cgroup-2
$ tree
.
├── cgroup-1
│ ├── cgroup.clone_children
│ ├── cgroup.event_control
│ ├── cgroup.procs
│ ├── notify_on_release
│ └── tasks
├── cgroup-2
│ ├── cgroup.clone_children
│ ├── cgroup.event_control
│ ├── cgroup.procs
│ ├── notify_on_release
│ └── tasks
├── cgroup.clone_children
├── cgroup.event_control
├── cgroup.procs
├── cgroup.sane_behavior
├── notify_on_release
├── release_agent
└── tasks
2 directories, 17 files
[root@localhost cgroup-test]# echo $$
2260
[root@localhost cgroup-test]# cat tasks | grep $$
2260
[root@localhost cgroup-test]# sh -c "echo $$ >> cgroup-1/tasks"
[root@localhost cgroup-test]# cat tasks | grep $$
[root@localhost cgroup-test]# echo $?
1
[root@localhost cgroup-test]# cat cgroup-1/tasks | grep $$
2260
# 使用下面这个命令可以发现当前进程已经被加到cgroup-test:/cgroup-1中了。
[root@localhost cgroup-test]# cat /proc/$$/cgroup
15:name=cgroup-test:/cgroup-1
11:cpuset:/
10:memory:/
9:hugetlb:/
8:cpuacct,cpu:/
7:perf_event:/
6:blkio:/
5:devices:/
4:net_prio,net_cls:/
3:pids:/
2:freezer:/
1:name=systemd:/user.slice/user-0.slice/session-21.scope
# 卸载hierarchy
$ umount cgroup-test
|
- important: 一个hierarchy可以附加多个subsystem
- important: 一个进程可以作为多个cgroup成员,但是这些cgroup必须在不同的hierarchy中。
- 一个进程fork出子进程时,子进程是和父进程在同一个cgroup中的,也可以根据需要将其移到其他cgroup中。
使用命令行来验证Cgroups(内存)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
# 安装stress
[memory]$ yum install -y epel-release stress
# 首先,在不做限制的情况下,启动一个占用内存的stress进程
[memory]$ stress --vm-bytes 400m --vm-keep -m 1
[memory]$ top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3315 root 20 0 416916 409792 124 R 100.0 10.6 1:13.74 stress
1 root 20 0 128196 6828 4172 S 0.0 0.2 0:01.65 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
4 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
5 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kworker/u4:0
6 root 20 0 0 0 0 S 0.0 0.0 0:00.14 ksoftirqd/0
7 root rt 0 0 0 0 S 0.0 0.0 0:00.03 migration/0
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
9 root 20 0 0 0 0 S 0.0 0.0 0:00.33 rcu_sched
10 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 lru-add-drain
# 创建一个cgroup
[memory]$ mkdir test-limit-memory && cd test-limit-memory
# 设置该cgroup的最大内存占用为200MB
[test-limit-memory]$ sh -c "echo '200m' > memory.limit_in_bytes"
# 将当前进程移动到这个cgroup中
[test-limit-memory]$ sh -c "echo $$ > tasks"
# 再次运行占用内存400MB的stress进程
[test-limit-memory]$ stress --vm-bytes 400m --vm-keep -m 1
# 在另一个终端执行top命令
$ top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3392 root 20 0 416916 204704 124 D 25.0 5.3 1:08.06 stress
6 root 20 0 0 0 0 S 0.3 0.0 0:00.69 ksoftirqd/0
9 root 20 0 0 0 0 R 0.3 0.0 0:01.04 rcu_sched
|
docker是如何使用Cgroups的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# docker run -m 设置内存限制
[root@localenv ~]# docker run -itd -m 128m ubuntu
Unable to find image 'ubuntu:latest' locally
latest: Pulling from library/ubuntu
6a5697faee43: Pull complete
ba13d3bc422b: Pull complete
a254829d9e55: Pull complete
Digest: sha256:fff16eea1a8ae92867721d90c59a75652ea66d29c05294e6e2f898704bdb8cf1
Status: Downloaded newer image for ubuntu:latest
25e470ba73f38094500b97645554f0e08642f33d6257e270608bf8ffbb187070
# docker会为每个容器在系统的hierarchy中创建cgroup
[root@localenv ~]# cd /sys/fs/cgroup/memory/docker/25e470ba73f38094500b97645554f0e08642f33d6257e270608bf8ffbb187070/
# 查看cgroup的内存限制
[root@localenv 25e470ba73f38094500b97645554f0e08642f33d6257e270608bf8ffbb187070]# cat memory.limit_in_bytes
134217728
# 查看cgroup中进程所使用的内存大小
[root@localenv 25e470ba73f38094500b97645554f0e08642f33d6257e270608bf8ffbb187070]# cat memory.usage_in_bytes
552960
|
使用命令行来验证Cgroups(CPU)
查看cpu hierarchy下含有哪些cpu这个subsystem的配置文件:
1
2
3
|
$ ls /sys/fs/cgroup/cpu
cgroup.clone_children cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release
cgroup.procs cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
|
如果熟悉Linux CPU管理的话,你就会在它的输出里注意到cfs_period和cfs_quota这样的关键词。这两个参数需要组合使用,可以用来限制进程在长度为cfs_period的一段时间内,只能被分配到总量为cfs_quota的CPU时间。
需要在/sys/fs/cgroup/cpu目录下创建一个子cgroup,container。不要直接使用/sys/fs/cgroup/cpu目录下的配置文件:
1
2
3
4
|
root@ubuntu:/sys/fs/cgroup/cpu$ mkdir container
root@ubuntu:/sys/fs/cgroup/cpu$ ls container/
cgroup.clone_children cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release
cgroup.procs cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
|
现在,我们在后台执行这样一条脚本:
1
2
|
$ while : ; do : ; done &
[1] 226
|
显然,它执行了一个死循环,可以把计算机的CPU吃到100%,根据它的输出,我们可以看到这个脚本在后台的进程号(PID)是226。
这样,我们可以用top指令来确认一下CPU有没有被打满:
1
2
|
$ top
%Cpu0 :100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
在输出里可以看到,CPU的使用率已经100%了(%Cpu0: 100.0 us)。
而此时,我们可以通过查看container目录下的文件,看到container控制组里的CPU quota还没有任何限制(即: -1),CPU period则是默认的100 ms(100000 us):
1
2
3
4
|
$ cat /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
-1
$ cat /sys/fs/cgroup/cpu/container/cpu.cfs_period_us
100000
|
接下来,我们可以通过修改这些文件的内容来设置限制:
比如,向container组里的cfs_quota文件写入20ms(20000 us):
1
|
$ echo 20000 > /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
|
结合前面的介绍,你应该能明白这个操作的含义,它意味着在每100ms的时间里,被该控制组限制的进程只能使用20ms的CPU时间,也就是说这个进程只能使用到20%的CPU带宽。
接下来,我们把被限制的进程的PID写入container组里的tasks文件,上面的设置就会对该进程生效了:
1
|
$ echo 226 > /sys/fs/cgroup/cpu/container/tasks
|
我们可以用top指令查看一下:
1
2
|
$ top
%Cpu0 : 20.3 us, 0.0 sy, 0.0 ni, 79.7 id, 0.0 wa, 0.0 hi, 0.0 hi, 0.0 si, 0.0 st
|
可以看到,计算机的CPU使用率立刻降到了20% (%Cpu0:20.3 us)。
我们可以在执行docker run时指定参数,来验证下控制组下面的资源文件里填上了什么值:
1
|
$ docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash
|
在启动这个容器后,我们可以通过查看Cgroups文件系统下,CPU子系统中,“docker"这个控制组里的资源限制文件的内容来确认:
1
2
3
4
|
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_period_us
100000
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_quota_us
20000
|
这就意味着这个Docker容器,只能使用到20%的CPU带宽。
用Go语言实现通过cgroup限制容器的资源
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
package main
import (
"os/exec"
"path"
"os"
"fmt"
"io/ioutil"
"syscall"
"strconv"
)
// 挂载了memory subsystem的hierarchy的根目录位置
const cgroupMemoryHierarchyMount = "/sys/fs/cgroup/memory"
func main() {
// 当自己调用自己的时候,就执行
if os.Args[0] == "/proc/self/exe" {
// 容器进程
println("子进程")
fmt.Printf("current pid %d", syscall.Getpid())
fmt.Println()
cmd := exec.Command("sh", "-c", `stress --vm-bytes 200m --vm-keep -m 1`)
cmd.SysProcAttr = &syscall.SysProcAttr{}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
fmt.Println(err)
os.Exit(1)
}
}
// clone一个子进程,并自己调用自己
println("父进程")
cmd := exec.Command("/proc/self/exe")
cmd.SysProcAttr = &syscall.SysProcAttr {
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Start(); err != nil {
fmt.Println("ERROR", err)
os.Exit(1)
}else {
// 得到fork出来进程映射在外部命名空间的pid
fmt.Printf("%v", cmd.Process.Pid)
// 在系统默认创建挂载了memory subsystem的Hierarchy上创建cgroup
os.Mkdir(path.Join(cgroupMemoryHierarchyMount, "testmemorylimit"), 0755)
// 将容器进程加入到这个cgroup中
ioutil.WriteFile(path.Join(cgroupMemoryHierarchyMount, "testmemorylimit", "tasks"), []byte(strconv.Itoa(cmd.Process.Pid)), 0644)
// 限制cgroup进程使用
ioutil.WriteFile(path.Join(cgroupMemoryHierarchyMount, "testmemorylimit", "memory.limit_in_bytes"), []byte("100m"), 0644)
}
cmd.Process.Wait()
}
|
通过对Cgroups虚拟文件系统的配置,将容器中stress进程的内存占用限制在了100MB(宿主机内存4GB,2.5%即100MB)
1
2
3
4
|
$ top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3745 root 20 0 212116 101992 124 R 22.7 2.6 0:25.03 stress
9 root 20 0 0 0 0 R 0.3 0.0 0:01.46 rcu_sched
|
将cgroup集成进IPC Namespace中的程序中,最终实现./test run -it -m 100m -cpuset 1 -cpushare 512 /bin/sh的效果:
为了适配各种各样的cgroup,所以创建了如下的cgroup.go文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
|
// 创建一个cgroup.go文件
package main
import (
"fmt"
"strings"
"os"
"path"
"bufio"
"io/ioutil"
"strconv"
)
// 1. 用于传递资源限制配置的结构体,包含内存限制,CPU时间片权重,CPU核心数
type ResourceConfig struct {
MemoryLimit string
CpuShare string
CpuSet string
}
// 2. Subsystem接口,每个Subsystem可以实现下面的4个接口
// 这里将cgroup抽象成了path,原因是cgroup在hierarchy的路径,便是虚拟文件系统中的虚拟路径
type Subsystem interface {
// 返回subsystem的名字,比如cpu memory
Name() string
// 设置某个cgroup在这个Subsystem中的资源限制
Set(path string, res *ResourceConfig) error
// 将进程添加到某个cgrou中
Apply(path string, pid int) error
// 移除某个cgroup
Remove(path string) error
}
// 3. 通过不同的subsystem初始化实例创建资源限制处理链数组
var (
SubsystemsIns = []Subsystem {
&CpusetSubSystem{},
&MemorySubSystem{},
&CpuSubSystem{},
}
)
// 3.1 memory subsystem的实现
type MemorySubSystem struct {
}
//a. 设置cgroupPath对应的cgroup的内存资源限制
func (s *MemorySubSystem) Set(cgroupPath string, res *ResourceConfig) error {
// GetCgroupPath的作用是获取当前subsystem在虚拟文件系统中的路径
if subsysCgroupPath, err := GetCgroupPath(s.Name(), cgroupPath, true); err == nil {
if res.MemoryLimit != "" {
// 设置这个cgroup的内存限制,即将限制写入到cgroup对应目录的memory.limit_in_bytes文件中
if err := ioutil.WriteFile(path.Join(subsysCgroupPath, "memory.limit_in_bytes"), []byte(res.MemoryLimit), 0644); err != nil {
return fmt.Errorf("set cgroup memory fail %v", err)
}
}
return nil
} else {
return err
}
}
//b. 删除cgroupPath对应的cgroup
func (s *MemorySubSystem) Remove(cgroupPath string) error {
if subsysCgroupPath, err := GetCgroupPath(s.Name(), cgroupPath, false); err == nil {
// 删除cgroup便是删除对应的cgroupPath的目录
return os.RemoveAll(subsysCgroupPath)
} else {
return err
}
}
//c. 将一个进程加入到cgroupPath对应的cgroup中
func (s *MemorySubSystem) Apply(cgroupPath string, pid int) error {
if subsysCgroupPath, err := GetCgroupPath(s.Name(), cgroupPath, false); err == nil {
// 把进程的PID写到cgroup的虚拟文件系统对应目录下的"task"文件中
if err := ioutil.WriteFile(path.Join(subsysCgroupPath, "tasks"), []byte(strconv.Itoa(pid)), 0644); err != nil {
return fmt.Errorf("set cgroup proc fail %v", err)
}
return nil
}else {
return fmt.Errorf("get cgroup %s error: %v", cgroupPath, err)
}
}
//d. 返回cgroup名字
func (s *MemorySubSystem) Name() string {
return "memory"
}
// 3.2 cpu subsystem的实现
type CpuSubSystem struct {
}
//a. 设置cgroupPath对应的cgroup的内存资源限制
func (s *CpuSubSystem) Set(cgroupPath string, res *ResourceConfig) error {
if subsysCgroupPath, err := GetCgroupPath(s.Name(), cgroupPath, true); err == nil {
if res.CpuShare != "" {
if err := ioutil.WriteFile(path.Join(subsysCgroupPath, "cpu.shares"), []byte(res.CpuShare), 0644); err != nil {
return fmt.Errorf("set cgroup cpu share fail %v", err)
}
}
return nil
} else {
return err
}
}
//b. 删除cgroupPath对应的cgroup
func (s *CpuSubSystem) Remove(cgroupPath string) error {
if subsysCgroupPath, err := GetCgroupPath(s.Name(), cgroupPath, false); err == nil {
return os.RemoveAll(subsysCgroupPath)
} else {
return err
}
}
//c. 将一个进程加入到cgroupPath对应的cgroup中
func (s *CpuSubSystem)Apply(cgroupPath string, pid int) error {
if subsysCgroupPath, err := GetCgroupPath(s.Name(), cgroupPath, false); err == nil {
if err := ioutil.WriteFile(path.Join(subsysCgroupPath, "tasks"), []byte(strconv.Itoa(pid)), 0644); err != nil {
return fmt.Errorf("set cgroup proc fail %v", err)
}
return nil
} else {
return fmt.Errorf("get cgroup %s error: %v", cgroupPath, err)
}
}
//d. 返回cgroup名字
func (s *CpuSubSystem) Name() string {
return "cpu"
}
// 3.3 cpuset subsystem的实现
type CpusetSubSystem struct {
}
//a. 设置cgroupPath对应的cgroup的内存资源限制
func (s *CpusetSubSystem) Set(cgroupPath string, res *ResourceConfig) error {
if subsysCgroupPath, err := GetCgroupPath(s.Name(), cgroupPath, true); err == nil {
if res.CpuSet != "" {
if err := ioutil.WriteFile(path.Join(subsysCgroupPath, "cpuset.cpus"), []byte(res.CpuSet), 0644); err != nil {
return fmt.Errorf("set cgroup cpuset fail %v", err)
}
}
return nil
} else {
return err
}
}
//b. 删除cgroupPath对应的cgroup
func (s *CpusetSubSystem) Remove(cgroupPath string) error {
if subsysCgroupPath, err := GetCgroupPath(s.Name(), cgroupPath, false); err == nil {
return os.RemoveAll(subsysCgroupPath)
} else {
return err
}
}
//c. 将一个进程加入到cgroupPath对应的cgroup中
func (s *CpusetSubSystem)Apply(cgroupPath string, pid int) error {
if subsysCgroupPath, err := GetCgroupPath(s.Name(), cgroupPath, false); err == nil {
if err := ioutil.WriteFile(path.Join(subsysCgroupPath, "tasks"), []byte(strconv.Itoa(pid)), 0644); err != nil {
return fmt.Errorf("set cgroup proc fail %v", err)
}
return nil
} else {
return fmt.Errorf("get cgroup %s error: %v", cgroupPath, err)
}
}
//d. 返回cgroup名字
func (s *CpusetSubSystem) Name() string {
return "cpuset"
}
// 4. 工具
// 4.1 通过/proc/self/mountinfo找出挂在了某个subsystem的hierarchy cgroup根节点所在的目录
// $ cat /proc/self/mountinfo | grep cgroup
// 24 17 0:20 / /sys/fs/cgroup ro,nosuid,nodev,noexec shared:8 - tmpfs tmpfs ro,seclabel,mode=755
// 25 24 0:21 / /sys/fs/cgroup/systemd rw,nosuid,nodev,noexec,relatime shared:9 - cgroup cgroup rw,seclabel,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd
// 27 24 0:23 / /sys/fs/cgroup/net_cls,net_prio rw,nosuid,nodev,noexec,relatime shared:10 - cgroup cgroup rw,seclabel,net_prio,net_cls
// 28 24 0:24 / /sys/fs/cgroup/blkio rw,nosuid,nodev,noexec,relatime shared:11 - cgroup cgroup rw,seclabel,blkio
// 29 24 0:25 / /sys/fs/cgroup/cpu,cpuacct rw,nosuid,nodev,noexec,relatime shared:12 - cgroup cgroup rw,seclabel,cpuacct,cpu
// 30 24 0:26 / /sys/fs/cgroup/devices rw,nosuid,nodev,noexec,relatime shared:13 - cgroup cgroup rw,seclabel,devices
// 31 24 0:27 / /sys/fs/cgroup/memory rw,nosuid,nodev,noexec,relatime shared:14 - cgroup cgroup rw,seclabel,memory
// 32 24 0:28 / /sys/fs/cgroup/cpuset rw,nosuid,nodev,noexec,relatime shared:15 - cgroup cgroup rw,seclabel,cpuset
// 33 24 0:29 / /sys/fs/cgroup/pids rw,nosuid,nodev,noexec,relatime shared:16 - cgroup cgroup rw,seclabel,pids
// 34 24 0:30 / /sys/fs/cgroup/freezer rw,nosuid,nodev,noexec,relatime shared:17 - cgroup cgroup rw,seclabel,freezer
// 35 24 0:31 / /sys/fs/cgroup/perf_event rw,nosuid,nodev,noexec,relatime shared:18 - cgroup cgroup rw,seclabel,perf_event
// 36 24 0:32 / /sys/fs/cgroup/hugetlb rw,nosuid,nodev,noexec,relatime shared:19 - cgroup cgroup rw,seclabel,hugetlb
func FindCgroupMountpoint(subsystem string) string {
f, err := os.Open("/proc/self/mountinfo")
if err != nil {
return ""
}
defer f.Close()
scanner := bufio.NewScanner(f)
for scanner.Scan() {
txt := scanner.Text()
fields := strings.Split(txt, " ")
for _, opt := range strings.Split(fields[len(fields)-1], ",") {
if opt == subsystem {
return fields[4]
}
}
}
if err := scanner.Err(); err != nil {
return ""
}
return ""
}
// 4.2 得到cgroup在文件系统中的绝对路径
func GetCgroupPath(subsystem string, cgroupPath string, autoCreate bool) (string, error) {
cgroupRoot := FindCgroupMountpoint(subsystem)
if _, err := os.Stat(path.Join(cgroupRoot, cgroupPath)); err == nil || (autoCreate && os.IsNotExist(err)) {
if os.IsNotExist(err) {
if err := os.Mkdir(path.Join(cgroupRoot, cgroupPath), 0755); err == nil {
} else {
return "", fmt.Errorf("error create cgroup %v", err)
}
}
return path.Join(cgroupRoot, cgroupPath), nil
} else {
return "", fmt.Errorf("cgroup path error %v", err)
}
}
// 5. 把这些不同subsystem中的cgroup管理起来,并与容器建立关系
type CgroupManager struct {
//cgroup在hierarchy中的路径,相当于创建的cgroup目录对应于各root cgroup目录的路径
Path string
// 资源配置
Resource *ResourceConfig
}
func NewCgroupManager(path string) *CgroupManager {
return &CgroupManager {
Path: path,
}
}
// 将进程PID加入到每个cgroup中
func (c *CgroupManager) Apply(pid int) error {
for _, subSysIns := range(SubsystemsIns) {
subSysIns.Apply(c.Path, pid)
}
return nil
}
// 设置各个subsystem挂载中的cgroup资源限制
func (c *CgroupManager) Set(res *ResourceConfig) error {
for _, subSysIns := range(SubsystemsIns) {
subSysIns.Set(c.Path, res)
}
return nil
}
// 释放各个subsystem挂载中的cgroup
func (c *CgroupManager) Destroy() error {
for _, subSysIns := range(SubsystemsIns) {
if err := subSysIns.Remove(c.Path); err != nil {
println("remove cgroup fail: %v", err)
}
}
return nil
}
|
然后,给上一节中介绍的程序中添加资源限制相关的标签,并在容器创建出来并初始化之后,将容器的进程加入到
各Subsystem挂载的cgroup中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
|
package main
import (
"os/exec"
"strings"
"syscall"
"os"
"log"
"flag"
"io/ioutil"
)
func NewPipe() (*os.File, *os.File, error) {
read, write, err := os.Pipe()
if err != nil {
return nil, nil, err
}
return read, write, nil
}
func readUserCommand() []string {
// uintptr(3)就是指index为3的文件描述符,也就是传递进来的管道的一端
// 第二参数表示文件的名字
pipe := os.NewFile(uintptr(3), "pipe")
msg, err := ioutil.ReadAll(pipe)
if err != nil {
println("init read pipe error: ", err.Error())
return nil
}
msgStr := string(msg)
return strings.Split(msgStr, " ")
}
func sendInitCommand(comArray []string, writePipe *os.File) {
command := strings.Join(comArray, " ")
println("command all is ", command)
writePipe.WriteString(command)
writePipe.Close()
}
func main() {
// 由于使用了管道,所以在调用init子命令的时候,是没有参数的
// 于是这里的3要改为2
if len(os.Args) < 2 {
println("parameter must greater than 1")
os.Exit(0)
}
cl := flag.NewFlagSet(os.Args[1], flag.ExitOnError)
switch os.Args[1] {
case "run":
// 设置option
var tty bool
var m, cpushare, cpuset string
cl.BoolVar(&tty, "it", false, "enable tty")
cl.StringVar(&m, "m", "", "memory limit")
cl.StringVar(&cpushare, "cpushare", "", "cpushare limit")
cl.StringVar(&cpuset, "cpuset", "", "cpuset limit")
cl.Parse(os.Args[2:])
if len(cl.Args()) < 1 {
println("Missing container command")
os.Exit(-1)
}
println("run..............")
readPipe, writePipe, err := NewPipe()
if err != nil {
println("New pipe error: ", err.Error())
os.Exit(-1)
}
cmd := exec.Command("/proc/self/exe", "init")
cmd.SysProcAttr = &syscall.SysProcAttr {
Cloneflags: syscall.CLONE_NEWUTS|syscall.CLONE_NEWIPC|syscall.CLONE_NEWPID|syscall.CLONE_NEWNS|syscall.CLONE_NEWNET|syscall.CLONE_NEWIPC,
}
println("tty", tty)
if tty {
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
}
// 注意,改动在这里,在这个地方传入管道文件读取端的句柄
// 管道是一个文件类型,肯定不能通过字符参数的方式进行传递,因此使用了command的cmd.ExtraFiles属性
// 这个属性的意思是会外带着这个文件句柄去创建子进程,可以使用命令`ll /proc/self/fd`来查看当前进程带着的所有文件描述符
// 由于,每个进程都会有三个默认的文件描述符,标准输入、标准输出、标准错误,所以这个外带的文件句柄就成了第四个。
cmd.ExtraFiles = []*os.File{readPipe}
// 运行父进程cmd
if err := cmd.Start(); err != nil {
log.Fatal(err)
}
// 注意,改动在这里,在这个地方添加对资源的限制
// use mydocker-cgroup as cgroup name
// 创建cgroup manager,并通过调用set和apply设置资源限制并使限制在容器上生效。
cgroupManager := NewCgroupManager("mydocker-cgroup")
defer cgroupManager.Destroy()
// 设置资源限制
res := &ResourceConfig{
MemoryLimit: m,
CpuSet: cpuset,
CpuShare: cpushare,
}
cgroupManager.Set(res)
// 将容器进程加入到每个cgroup中
cgroupManager.Apply(cmd.Process.Pid)
// 发送用户命令
sendInitCommand(cl.Args(), writePipe)
cmd.Wait()
os.Exit(-1)
case "init":
cmdArray := readUserCommand()
if cmdArray == nil || len(cmdArray) == 0 {
println("Run container get user command error, cmdArray is nil")
os.Exit(-1)
}
println("command is ", strings.Join(cmdArray, " "))
// 如果你的机器的根目录的挂载类型是shared,那必须先重新挂载根目录mount --make-rprivate
if err := syscall.Mount("","/","",syscall.MS_PRIVATE|syscall.MS_REC, ""); err != nil {
log.Fatal("make parent mount private error: %v", err)
}
// MS_NOEXEC: 在文件系统中不允许运行其他程序
// MS_NOSUID: 在本系统中运行程序的时候,不允许set-user-ID或set-group-ID
// MS_NODEV: 这个参数是自从Linux2.4以来,所有mount的系统都会默认设定的参数
defaultMountFlags := syscall.MS_NOEXEC | syscall.MS_NOSUID | syscall.MS_NODEV
syscall.Mount("proc", "/proc", "proc", uintptr(defaultMountFlags), "")
// 改动,调用exec.LookPath, 可以在系统的PATH里面寻找命令的绝对路径
path, err := exec.LookPath(cmdArray[0])
if err != nil {
println("Exec loop path error : ", err.Error())
os.Exit(-1)
}
println("Find path: ", path)
if err := syscall.Exec(path, cmdArray[0:], os.Environ()); err != nil {
println(err.Error())
}
default:
println("Usage: ./test run|init")
os.Exit(2)
}
}
|
3. 深入理解容器镜像
注意:如果你的Linux使用的是OverlayFS,请使用overlay2作为驱动而不是overlay,因为overlay2在inode利用率上更高效。
使用overlay要求Linux内核版本在3.18或者更高并加载了覆盖内核模块,使用overlay2要求Linux内核版本在4.0或者更高(RHEL和CentOS的版本需要为3.10.0-514或者更高)。
写时复制(CoW, Copy-on-Write): OverlayFS采用写时复制策略来处理对只读层文件的修改。这意味着当容器或应用试图修改一个位于只读层的文件时,该文件会被复制到可读写层(upperdir),然后在可读写层上进行修改。如果频繁修改小文件,会导致许多相似副本的累积,从而占用更多空间,即使这些文件原本只做了微小的改动。
overlay2是overlay的一个进化版本,它在保留了基本的写时复制机制的同时,针对inode管理、性能和存储效率进行了优化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
#define _GNU_SOURCE
#include <sys/mount.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
static char container_stack[STACK_SIZE];
char* const container_args[] = {
"/bin/bash",
NULL
};
int container_main(void* arg)
{
printf("Container - inside the container!\n");
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
int main()
{
printf("Parent - start a container!\n");
int container_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWNS | SIGCHLD, NULL);
waitpid(container_pid, NULL, 0);
printf("Parent - container stopped!\n");
return 0;
}
|
这段代码的功能非常简单:在main函数里,我们通过clone()系统调用创建了一个新的子进程container_main, 并且声明要为它启用Mount Namespace (即: CLONE_NEWNS标志)。
而这个子进程执行的,是一个”/bin/bash"程序,也就是一个shell。所以这个shell就运行在了Mount Namespace的隔离环境中。
我们来一起编译一下这个程序:
1
2
3
4
|
$ gcc -o ns ns.c
$ ./ns
Parent - start a container!
Contaier - inside the container!
|
这样,我们就进入了这个"容器"当中。可是,如果在"容器"里执行一下ls指令的话,我们就会发现一个有趣的现象: /tmp目录下的内容跟宿主机的内容是一样的。
1
2
|
$ ls /tmp
# 你会看到好多宿主机的文件
|
也就是说:
即使开启了Mount Namespace,容器进程看到的文件系统也跟宿主机完全一样。
这是怎么回事呢?
仔细思考一下, 你会发现这其实并不难理解:Mount Namespace修改的,是容器进程对文件系统"挂载点"的认知。但是,这也就意味着,只有在"挂载"这个操作发生之后,进程的视图才会被改变。而在此之前,新创建的容器会直接继承宿主机的各个挂载点。
这时,你可能已经想到了一个解决办法:创建新进程时,除了声明要启用Mount Namespace之外,我们还可以告诉容器进程,有哪些目录需要重新挂载,就比如这个/tmp目录。于是,我们在容器进程执行前可以添加一步重新挂载/tmp目录的操作:
1
2
3
4
5
6
7
8
9
10
|
int container_main(void* arg)
{
printf("Container - inside the container!\n");
// 如果你的机器的根目录的挂载类型是shared,那必须先重新挂载根目录
mount("", "/", NULL, MS_PRIVATE, "");
mount("none", "/tmp", "tmpfs", 0, "");
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
|
可以看到,在修改后的代码里,我在容器进程启动之前,加上了一句mount(“none”, “/tmp”, “tmpfs”, 0, “")语句。 就这样,我告诉了容器以tmpfs(内存盘)格式,重新挂在了/tmp目录。
这段修改后的代码,编译执行后的结果又如何呢?我们可以试验一下:
1
2
3
4
5
|
$ gcc -o ns ns.c
$ ./ns
Parent - start a container !
Container - inside the container!
$ ls /tmp
|
可以看到, 这次/tmp变成了一个空目录,这意味着重新挂载生效了。我们可以用mount -l检查一下:
1
2
|
$ mount -l | grep tmpfs
none on /tmp type tmpfs (rw,relatime)
|
可以看到,容器里的/tmp目录是以tmpfs方式单独挂载的。
更重要的是,因为我们创建的新进程启用了Mount Namespace,所以这次重新挂载的操作,只在容器进程的Mount Namespace中有效。如果在宿主机上用mount -l来检查一下这个挂载,你会发现它是不存在的:
1
2
|
# 在宿主机上
$ mount -l | grep tmpfs
|
这就是Mount Namespace跟其他Namespace的使用略有不同的地方:它对容器进程视图的改变,一定是伴随着挂载操作(mount)才能生效。
rootfs
可是,作为一个普通用户,我们希望的是一个更友好的情况:每当创建一个新容器时,我希望容器进程看到的文件系统就是一个独立的隔离环境,而不是继承自宿主机的文件系统。怎么才能做到这一点呢?
在Linux操作系统里,有一个名为chroot的命令可以帮助你在shell中方便地完成这个工作。顾名思义,它的作用就是帮你"change root file system”,即改变进程的根目录到你指定的位置。它的用法也非常简单。
假设,我们现在有一个$HOME/test目录,想要把它作为一个/bin/bash进程的根目录。
首先,创建一个test目录和几个lib文件夹:
1
2
3
|
$ mkdir -p $HOME/test
$ mkdir -p $HOME/test/{bin,lib64,lib}
$ cd $HOME/test
|
然后,把bash命令拷贝到test目录对应的bin目录下:
1
|
$ cp -v /bin/{bash,ls} $HOME/test/bin
|
接下来,把bash命令需要的所有so文件,也拷贝到test目录对应的lib路径下。找到so文件可以用ldd命令:
1
2
3
|
$ T=$HOME/test
$ list="$(ldd /bin/ls | egrep -o '/lib.*\.[0-9]')"
$ for i in $list; do cp -v "$i" "${T}${i}"; done
|
最后,执行chroot命令,告诉操作系统,我们将使用$HOME/test目录作为/bin/bash进程的根目录:
1
|
$ chroot $HOME/test /bin/bash
|
这时,你如果执行"ls /",就会看到,它返回的都是$HOME/test目录下面的内容,而不是宿主机的内容。
更重要的是,对于被chroot的进程来说,它并不会感受到自己的根目录已经被"修改"成$HOME/test了。
这种视图被修改的原理,是不是跟我之前介绍的Linux Namespace很类似呢?
没错!
实际上,Mount Namespace正是基于对chroot的不断改良才被发明出来的,它也是Linux操作系统里的第一个Namespace。
当然,为了能够让容器的这个根目录看起来更"真实",我们一般会在这个容器的根目录下挂载一个完整操作系统的文件系统, 比如Ubuntu16.04的ISO。这样,在容器启动之后,我们在容器里通过执行"ls /“查看根目录下的内容,就是Ubuntu 16.04的所有目录和文件。
而这个挂载在容器根目录上,用来为容器进程提供隔离后执行环境的文件系统,就是所谓的"容器镜像”。它还有一个更为专业的名字,叫作:rootfs(根文件系统)。
所以,一个最常见的rootfs,或者说容器镜像,会包括如下所示的一些目录和文件,比如/bin, /etc, /proc等等:
1
2
|
$ ls /
bin dev etc home lib lib64 mnt opt proc root run sbin sys tmp usr var
|
而你进入容器之后执行的/bin/bash,就是/bin目录下的可执行文件,与宿主机的/bin/bash完全不同。
现在,你应该可以理解,对Docker项目来说,它最核心的原理实际上就是为待创建的用户进程:
- 启用Linux Namespace配置;
- 设置指定的Cgroups参数;
- 切换进程的根目录(Change Root)。
这样,一个完整的容器就诞生了。不过,Docker项目在最后一步的切换上会优先使用pivot_root系统调用,如果系统不支持,才会使用chroot。
pivot_root是一个系统调用,主要功能是去改变当前的root文件系统。pivot_root可以将当前进程的root文件系统移动到put_old文件夹中,
然后使new_root成为新的root文件系统。new_root和put_old必须不能同时存在当前root的同一个文件系统中。
在golang中,pivot_root的定义是这样的:func PivotRoot(newroot string, putold string) (err error)
pivot_root和chroot的主要区别是:pivot_root是把整个系统切换到一个新的root目录,而移除对之前root文件系统的依赖,
这样你就能够umount原先的root文件系统。而chroot是针对某个进程,系统的其他部分依旧运行于老的root目录中。
这里以busybox的rootfs为例,首先要在另一个装有docker的机器上获取busybox的文件系统:
1
2
3
4
5
|
$ docker pull busybox:1.32.0
# 获取容器id, 通过docker container ls获取的container-id不是很全
$ docker run -d busybox:1.32.0 top -b
$ docker export -o busybox.tar `docker run -d busybox:1.32.0 top -b`
$ tar -xvf busybox.tar
|
使用golang来实现rootfs:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
|
package main
import (
"os/exec"
"strings"
"syscall"
"os"
"path/filepath"
"log"
"fmt"
"flag"
"io/ioutil"
)
var (
mntURL = "/root/mnt"
rootURL= "/root/"
)
func NewPipe() (*os.File, *os.File, error) {
read, write, err := os.Pipe()
if err != nil {
return nil, nil, err
}
return read, write, nil
}
func readUserCommand() []string {
// uintptr(3)就是指index为3的文件描述符,也就是传递进来的管道的一端
// 第二参数表示文件的名字
pipe := os.NewFile(uintptr(3), "pipe")
msg, err := ioutil.ReadAll(pipe)
if err != nil {
println("init read pipe error: ", err.Error())
return nil
}
msgStr := string(msg)
return strings.Split(msgStr, " ")
}
func sendInitCommand(comArray []string, writePipe *os.File) {
command := strings.Join(comArray, " ")
println("command all is ", command)
writePipe.WriteString(command)
writePipe.Close()
}
func main() {
// 由于使用了管道,所以在调用init子命令的时候,是没有参数的
// 于是这里的3要改为2
if len(os.Args) < 2 {
println("parameter must greater than 1")
os.Exit(0)
}
cl := flag.NewFlagSet(os.Args[1], flag.ExitOnError)
switch os.Args[1] {
case "run":
// 设置option
var tty bool
var m, cpushare, cpuset string
cl.BoolVar(&tty, "it", false, "enable tty")
cl.StringVar(&m, "m", "", "memory limit")
cl.StringVar(&cpushare, "cpushare", "", "cpushare limit")
cl.StringVar(&cpuset, "cpuset", "", "cpuset limit")
cl.Parse(os.Args[2:])
if len(cl.Args()) < 1 {
println("Missing container command")
os.Exit(-1)
}
println("run..............")
// 1.改动
readPipe, writePipe, err := NewPipe()
if err != nil {
println("New pipe error: ", err.Error())
os.Exit(-1)
}
cmd := exec.Command("/proc/self/exe", "init")
cmd.SysProcAttr = &syscall.SysProcAttr {
Cloneflags: syscall.CLONE_NEWUTS|syscall.CLONE_NEWIPC|syscall.CLONE_NEWPID|syscall.CLONE_NEWNS|syscall.CLONE_NEWNET|syscall.CLONE_NEWIPC,
}
println("tty", tty)
if tty {
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
}
// 1.注意,改动在这里,在这个地方传入管道文件读取端的句柄
// 管道是一个文件类型,肯定不能通过字符参数的方式进行传递,因此使用了command的cmd.ExtraFiles属性
// 这个属性的意思是会外带着这个文件句柄去创建子进程,可以使用命令`ll /proc/self/fd`来查看当前进程带着的所有文件描述符
// 由于,每个进程都会有三个默认的文件描述符,标准输入、标准输出、标准错误,所以这个外带的文件句柄就成了第四个。
cmd.ExtraFiles = []*os.File{readPipe}
// 3. 改动
// 在启动父进程之前,设置它的当前路径
// 这个路径非常关键,后面的pivotRoot操作,会使用到这个当前路径
NewWorkSpace(rootURL, mntURL)
cmd.Dir = mntURL
// 运行父进程cmd
if err := cmd.Start(); err != nil {
log.Fatal(err)
}
// 2.注意,改动在这里,在这个地方添加对资源的限制
// use mydocker-cgroup as cgroup name
// 创建cgroup manager,并通过调用set和apply设置资源限制并使限制在容器上生效。
cgroupManager := NewCgroupManager("mydocker-cgroup")
defer cgroupManager.Destroy()
// 设置资源限制
res := &ResourceConfig{
MemoryLimit: m,
CpuSet: cpuset,
CpuShare: cpushare,
}
cgroupManager.Set(res)
// 将容器进程加入到每个cgroup中
cgroupManager.Apply(cmd.Process.Pid)
// 1.发送用户命令
sendInitCommand(cl.Args(), writePipe)
cmd.Wait()
// 3. 改动:
// docker会在删除容器的时候,把容器对应的Write Layer和Container-init Layer删除,而保留镜像所有的内容
// 在这里,我们简化为只删除Write Layer (Container-init的处理,非常复杂)
DeleteWorkSpace(rootURL, mntURL)
os.Exit(-1)
case "init":
// 1.获取用户命令
cmdArray := readUserCommand()
if cmdArray == nil || len(cmdArray) == 0 {
println("Run container get user command error, cmdArray is nil")
os.Exit(-1)
}
println("command is ", strings.Join(cmdArray, " "))
// 如果你的机器的根目录的挂载类型是shared,那必须先重新挂载根目录mount --make-rprivate
if err := syscall.Mount("","/","",syscall.MS_PRIVATE|syscall.MS_REC, ""); err != nil {
log.Fatal("make parent mount private error: %v", err)
}
// MS_NOEXEC: 在文件系统中不允许运行其他程序
// MS_NOSUID: 在本系统中运行程序的时候,不允许set-user-ID或set-group-ID
// MS_NODEV: 这个参数是自从Linux2.4以来,所有mount的系统都会默认设定的参数
defaultMountFlags := syscall.MS_NOEXEC | syscall.MS_NOSUID | syscall.MS_NODEV
syscall.Mount("proc", "/proc", "proc", uintptr(defaultMountFlags), "")
// 3. 改动,调用PivotRoot方法,将当前目录设置为容器内的根目录(所以,在执行程序是,需要先cd到busybox的rootfs目录下)
// 注意,在执行之前,需要给宿主机的PATH环境变量添加/bin路径,因为容器会使用宿主机的PATH环境变量的值。
path_v := os.Getenv("PATH")
if !strings.HasPrefix(path_v, "/bin") && !strings.Contains(path_v, ":/bin") {
path_v = path_v + ":/bin"
os.Setenv("PATH", path_v)
}
println("PATH environment variable is ", path_v)
setUpMount()
// 改动,调用exec.LookPath, 可以在系统的PATH里面寻找命令的绝对路径
path, err := exec.LookPath(cmdArray[0])
if err != nil {
println("Exec loop path error : ", err.Error())
os.Exit(-1)
}
println("Find path: ", path)
if err := syscall.Exec(path, cmdArray[0:], os.Environ()); err != nil {
println(err.Error())
}
default:
println("Usage: ./test run|init")
os.Exit(2)
}
}
// 在init子命令中,使用pivotRoot进行一系列的mount操作
func setUpMount() {
// 获取当前路径
pwd, err := os.Getwd()
if err != nil {
println("Get current location error %v", err)
return
}
println("Current location is %s", pwd)
pivotRoot(pwd)
// mount proc
defaultMountFlags := syscall.MS_NOEXEC | syscall.MS_NOSUID | syscall.MS_NODEV
syscall.Mount("proc", "/proc", "proc", uintptr(defaultMountFlags), "")
// tmpfs是一种基于内存的文件系统,可以使用RAM或swap分区来存储。
syscall.Mount("tmpfs", "/dev", "tmpfs", syscall.MS_NOSUID|syscall.MS_STRICTATIME, "mode=755")
}
// 注意,新增的代码(实现rootfs)
func pivotRoot(root string) error {
// 为了使当前root的老root和新root不在同一个文件系统下,我们把root重新mount了一次
// bind mount是把相同的内容换了一个挂载点的挂载方法
if err := syscall.Mount(root, root, "bind", syscall.MS_BIND|syscall.MS_REC, ""); err != nil {
return fmt.Errorf("Mount rootfs to itself error: %v", err)
}
// 创建rootfs/.pivot_root 存储 old_root
pivotDir := filepath.Join(root, ".pivot_root")
if err := os.Mkdir(pivotDir, 0777); err != nil {
return err
}
// pivot_root到新的rootfs,老的old_root现在挂载在rootfs/.pivot_root上
// 挂载点目前依然可以在mount命令中看到
if err := syscall.PivotRoot(root, pivotDir); err != nil {
return fmt.Errorf("pivot_root %v", err)
}
// 修改当前的工作目录到根目录
if err := syscall.Chdir("/"); err != nil {
return fmt.Errorf("chdir / %v", err)
}
pivotDir = filepath.Join("/", ".pivot_root")
// umount rootfs/.pivot_root
if err := syscall.Unmount(pivotDir, syscall.MNT_DETACH); err != nil {
return fmt.Errorf("unmount pivot_root dir %v", err)
}
// 删除临时文件夹
return os.Remove(pivotDir)
}
// 使用overlay包装busybox(rootfs)
//Create a overlay filesystem as container root workspace
func NewWorkSpace(rootURL string, mntURL string) {
CreateReadOnlyLayer(rootURL)
CreateWriteLayer(rootURL)
CreateMountPoint(rootURL, mntURL)
}
func CreateReadOnlyLayer(rootURL string) {
busyboxURL := rootURL + "busybox/"
busyboxTarURL := rootURL + "busybox.tar"
exist, err := PathExists(busyboxURL)
if err != nil {
fmt.Printf("Fail to judge whether dir %s exists. %v\n", busyboxURL, err)
}
if exist == false {
if err := os.Mkdir(busyboxURL, 0777); err != nil {
fmt.Printf("Mkdir dir %s error. %v\n", busyboxURL, err)
}
if _, err := exec.Command("tar", "-xvf", busyboxTarURL, "-C", busyboxURL).CombinedOutput(); err != nil {
fmt.Printf("Untar dir %s error %v\n", busyboxURL, err)
}
}
}
func CreateWriteLayer(rootURL string) {
writeURL := rootURL + "writeLayer/"
if err := os.Mkdir(writeURL, 0777); err != nil {
fmt.Printf("Mkdir dir %s error. %v\n", writeURL, err)
}
}
func CreateMountPoint(rootURL string, mntURL string) {
if err := os.Mkdir(mntURL, 0777); err != nil {
fmt.Printf("Mkdir dir %s error. %v\n", mntURL, err)
}
workLayer := rootURL+"workLayer"
if err := os.Mkdir(workLayer, 0777); err != nil {
fmt.Printf("Mkdir dir %s error. %v\n", mntURL, err)
}
// 注意,在这里需要使用到overlay文件系统
cmd := exec.Command("mount", "-t", "overlay", "-o", fmt.Sprintf("lowerdir=%s,upperdir=%s,workdir=%s", rootURL+"busybox/", rootURL+"writeLayer", workLayer), "none", mntURL)
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
println(err.Error())
}
}
//Delete the overlay filesystem while container exit
func DeleteWorkSpace(rootURL string, mntURL string){
DeleteMountPoint(rootURL, mntURL)
DeleteWriteLayer(rootURL)
}
func DeleteMountPoint(rootURL string, mntURL string){
cmd := exec.Command("umount", mntURL)
cmd.Stdout=os.Stdout
cmd.Stderr=os.Stderr
if err := cmd.Run(); err != nil {
println(err)
}
if err := os.RemoveAll(mntURL); err != nil {
fmt.Printf("Remove dir %s error %v\n", mntURL, err)
}
}
func DeleteWriteLayer(rootURL string) {
writeURL := rootURL + "writeLayer/"
if err := os.RemoveAll(writeURL); err != nil {
fmt.Printf("Remove dir %s error %v\n", writeURL, err)
}
workURL := rootURL + "workLayer/"
if err := os.RemoveAll(workURL); err != nil {
fmt.Printf("Remove dir %s error %v\n", workURL, err)
}
}
func PathExists(path string) (bool, error) {
_, err := os.Stat(path)
if err == nil {
return true, nil
}
if os.IsNotExist(err) {
return false, nil
}
return false, err
}
|
OverlayFS
这时你可能已经发现了另一个非常棘手的问题:难道我每开发一个应用,或者升级一下现有的应用,都要重复制作一次rootfs吗?
一种比较直观的解决办法是,我在制作rootfs的时候,每做一步"有意义"的操作,就保存一个rootfs出来,这样其他同事就可以按需去用他需要的rootfs了。
但是,这个解决办法并不具备推广性。原因在于,一旦你的同事们修改了这个rootfs,新旧两个rootfs之间就没有任何关系了。这样做的结果就是极度的碎片化。
那么,既然这些修改都基于一个旧的rootfs,我们能不能以增量的方式去做这些修改呢?
这样做的好处是,所有人都只需要维护相对于base rootfs修改的增量内容,而不是每次修改都创造一个"fork"。
答案当然是肯定的。
这也正是为何,Docker公司在实现Docker镜像时并没有沿用以前制作rootfs的标准流程,而是做了一个小小的创新:
Docker在镜像的设计中,引入了层(layer)的概念。也就是说,用户制作镜像的每一步操作,都会生成一个层,也就是一个增量rootfs。
当然,这个想法不是凭空臆造出来的,而是用了一种叫做联合文件系统(Union File System)的能力。
Union File System也叫做UnionFS, 最主要的功能是将多个不同位置的目录联合挂载(union mount)到同一个目录下。比如,我现在有两个目录A和B,它们分别有两个文件:
1
2
3
4
5
6
7
8
|
$ tree
.
├── A
│ ├── a
│ └── x
└── B
├── b
└── x
|
然后,我使用联合挂载的方式,将这两个目录挂载到一个公共的目录C上:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
$ mkdir C
$ mkdir D
# The lower directory can be read-only or could be an overlay itself.
# The upper directory is normally writable.
# The workdir is used to prepare files as they are switched between the layers.
$ mount -t overlay -o lowerdir=./A,upperdir=./B,workdir=./D none ./C/
$ tree
├── A
│ ├── a
│ └── x
├── B
│ ├── b
│ └── x
├── C
│ ├── a
│ ├── b
│ └── x
└── D
└── work
|
从上面的执行结果可以看出,目录A和B下的文件被合并到了一起。
这时,我再查看目录C的内容,就能看到目录A和B下的文件被合并到了一起:
1
2
3
4
5
|
$ tree ./C
./C
├── a
├── b
└── x
|
可以看到,在这个合并后的目录C里,有a、b、x三个文件,并且x文件只有一份。这,就是"合并"的含义。此外,如果你在目录C里对a、b、x文件做修改,这些修改也会在对应的目录A、B中生效。
那么,在Docker项目中,又是如何使用这种Union File System的呢?
我的环境是CentOS 7和Docker CE 18.05, 这对组合默认使用的是Overlay这个联合文件系统的实现。你可以通过docker info命令,查看到这个信息(查看Storage Driver这项)。
现在,我们启动一个容器,比如:
1
|
$ docker run -d ubuntu:20.04 sleep 3600
|
这个时候,Docker就会从Docker Hub上拉取一个Ubuntu镜像到本地。
这个所谓的"镜像",实际上就是一个Ubuntu操作系统的rootfs,它的内容是Ubuntu操作系统的所有文件和目录。不过,与之前我们讲述的rootfs稍微不同的是,Docker镜像使用的rootfs,往往由多个"层"组成:
1
2
3
4
5
6
7
8
9
10
11
|
$ docker image inspect ubuntu:20.04
...
"RootFS": {
"Type": "layers",
"Layers": [
"sha256:47dde53750b4a8ed24acebe52cf31ad131e73a9611048fc2f92c9b6274ab4bf3",
"sha256:0c2689e3f9206b1c4adfb16a1976d25bd270755e734588409b31ef29e3e756d6",
"sha256:cc9d18e90faad04bc3893cfaa50b7846ee75f48f5b8377a213fa52af2189095c"
]
},
...
|
可以看到,这个Ubuntu镜像,实际上由3个层组成。这3个层就是3个增量rootfs,每一层都是Ubuntu操作系统文件和目录的一部分;而在使用镜像时,Docker会把这些增量联合挂载在一个统一的挂载点上(等价于前面例子里的"/C"目录)。
1
2
|
$ mount -t overlay
overlay on /var/lib/docker/overlay2/f7408543e68309c45bfe82bbe3749fc2695a3ebaa7c28cf270321075811a05c4/merged type overlay (rw,relatime,seclabel,lowerdir=/var/lib/docker/overlay2/l/OM2WERKCCHTYETF2YWWJWDDFB7:/var/lib/docker/overlay2/l/XXXTE6463EKOE7EL3H57OHGFXM:/var/lib/docker/overlay2/l/OEKTZOT5LOJ2QZ526VBXT4LGDF:/var/lib/docker/overlay2/l/ACJQW4UG3UHTCV5DCV3HE4CMBQ,upperdir=/var/lib/docker/overlay2/f7408543e68309c45bfe82bbe3749fc2695a3ebaa7c28cf270321075811a05c4/diff,workdir=/var/lib/docker/overlay2/f7408543e68309c45bfe82bbe3749fc2695a3ebaa7c28cf270321075811a05c4/work)
|
我们整理下lowerdir,upperdir, mergeddir
lowerdir:
/var/lib/docker/overlay2/l/OM2WERKCCHTYETF2YWWJWDDFB7
/var/lib/docker/overlay2/l/XXXTE6463EKOE7EL3H57OHGFXM
/var/lib/docker/overlay2/l/OEKTZOT5LOJ2QZ526VBXT4LGDF
/var/lib/docker/overlay2/l/ACJQW4UG3UHTCV5DCV3HE4CMBQ
upperdir:
/var/lib/docker/overlay2/f7408543e68309c45bfe82bbe3749fc2695a3ebaa7c28cf270321075811a05c4/diff
mergeddir:
/var/lib/docker/overlay2/f7408543e68309c45bfe82bbe3749fc2695a3ebaa7c28cf270321075811a05c4/merged
不出意外的,这个mergeddir目录里面正是一个完整的Ubuntu操作系统。
1
2
|
$ ls /var/lib/docker/overlay2/f7408543e68309c45bfe82bbe3749fc2695a3ebaa7c28cf270321075811a05c4/merged
bin boot dev etc home lib lib32 lib64 libx32 media mnt opt proc root run sbin srv sys tmp usr var
|
那么,前面提到的3个镜像层,又是如何被联合挂载成这样一个完整的Ubuntu文件系统的呢?
1
2
3
4
5
6
7
8
9
10
11
12
|
[overlay2]# ls
03c017dfbdbbd3e623586b82648637c07c94cec9a232e445ed202fe0d51e5ff3 backingFsBlockDev l
64943c1a5bc5d57f0b6fda953b69f25a8facc8de648a2b4fd92284640a55ec67 f7408543e68309c45bfe82bbe3749fc2695a3ebaa7c28cf270321075811a05c4
8b4c033c58d2e4a947dab0a43703c690960fb3417d680cbea953cfe227d1caa8 f7408543e68309c45bfe82bbe3749fc2695a3ebaa7c28cf270321075811a05c4-init
[overlay2]#
[overlay2]# ls -l l/
总用量 0
lrwxrwxrwx. 1 root root 72 11月 4 00:37 ACJQW4UG3UHTCV5DCV3HE4CMBQ -> ../03c017dfbdbbd3e623586b82648637c07c94cec9a232e445ed202fe0d51e5ff3/diff
lrwxrwxrwx. 1 root root 72 11月 4 00:37 OEKTZOT5LOJ2QZ526VBXT4LGDF -> ../8b4c033c58d2e4a947dab0a43703c690960fb3417d680cbea953cfe227d1caa8/diff
lrwxrwxrwx. 1 root root 77 11月 4 00:37 OM2WERKCCHTYETF2YWWJWDDFB7 -> ../f7408543e68309c45bfe82bbe3749fc2695a3ebaa7c28cf270321075811a05c4-init/diff
lrwxrwxrwx. 1 root root 72 11月 4 00:37 WAEXJZZMUB3YBLVREZMRZD4X3Y -> ../f7408543e68309c45bfe82bbe3749fc2695a3ebaa7c28cf270321075811a05c4/diff
lrwxrwxrwx. 1 root root 72 11月 4 00:37 XXXTE6463EKOE7EL3H57OHGFXM -> ../64943c1a5bc5d57f0b6fda953b69f25a8facc8de648a2b4fd92284640a55ec67/diff
|
我们对上面的输出做个整理:
1. lowerdir: (ro+wh)
/var/lib/docker/overlay2/l/OM2WERKCCHTYETF2YWWJWDDFB7 -> f7408543e68309c45bfe82bbe3749fc2695a3ebaa7c28cf270321075811a05c4-init/diff
/var/lib/docker/overlay2/l/XXXTE6463EKOE7EL3H57OHGFXM -> 64943c1a5bc5d57f0b6fda953b69f25a8facc8de648a2b4fd92284640a55ec67/diff
/var/lib/docker/overlay2/l/OEKTZOT5LOJ2QZ526VBXT4LGDF -> 8b4c033c58d2e4a947dab0a43703c690960fb3417d680cbea953cfe227d1caa8/diff
/var/lib/docker/overlay2/l/ACJQW4UG3UHTCV5DCV3HE4CMBQ -> 03c017dfbdbbd3e623586b82648637c07c94cec9a232e445ed202fe0d51e5ff3/diff
2. upperdir: (rw)
/var/lib/docker/overlay2/l/WAEXJZZMUB3YBLVREZMRZD4X3Y -> f7408543e68309c45bfe82bbe3749fc2695a3ebaa7c28cf270321075811a05c4/diff
从整理的结果来看,这个容器的rootfs由下面的两部分组成:
第一部分,只读层(lowerdir)。
出去init层,正好对应上ubuntu:20.04镜像的3层。可以看到,它们的挂载方式都是只读的(ro+wh, 即readonly+whiteout, 至于什么是whiteout, 我下面马上会讲到)。
这时,我们可以分别查看一下这些层的内容:
$ ls 64943c1a5bc5d57f0b6fda953b69f25a8facc8de648a2b4fd92284640a55ec67/diff
run
$ ls 8b4c033c58d2e4a947dab0a43703c690960fb3417d680cbea953cfe227d1caa8/diff
etc usr var
$ ls 03c017dfbdbbd3e623586b82648637c07c94cec9a232e445ed202fe0d51e5ff3/diff
bin boot dev etc home lib lib32 lib64 libx32 media mnt opt proc root run sbin srv sys tmp usr var
可以看到,这些层,都以增量的方式分别包含了Ubuntu操作系统的一部分。
在lowerdir中有一个非常特殊的一层,文件夹名以-init结尾。Init层是Docker项目单独生成的一个内部层,专门用来存放/etc/hosts、/etc/resolv.conf等信息。
需要这样一层的原因是,这些文件本来属于只读的Ubuntu镜像的一部分,但是用户往往需要在启动容器时写入一些指定的值比如hostname,所以就需要在可读写层对它们进行修改。
可是,这些修改往往只对当前的容器有效,我们并不希望执行docker commit时,把这些信息连同可读写层一起提交掉。
所以,Docker做法是,在修改了这些文件之后,以一个单独的层挂载了出来。而用户执行docker commit只会提交可读写层,所以是不包含这些内容的。
第二部分,可读写层(upperdir)。
在没有写入文件之前,这个目录是空的。而一旦在容器里做了写操作,你修改产生的内容就会以增量的方式出现在这个层中。
可是,你有没有想到这样一个问题: 如果我现在要做的,是删除只读层里的一个文件呢?
为了实现这样的删除操作,overlay会在可读写层创建一个whiteout文件,把只读层里的文件"遮挡"起来。
比如,你要删除只读层里一个名叫foo的文件,那么这个删除操作实际上是在可读写层创建了一个名叫.wh.foo的文件。这样,当这两个层被联合挂载之后,foo文件就会被.wh.foo文件"遮挡"起来,“消失"了。这个功能,就是"ro+wh"的挂载方式,即只读 + whiteout的含义。我喜欢把whiteout形象地翻译为: “白障”。
所以,最上面这个可读写层的作用,就是专门用来存放你修改rootfs后产生的增量,无论是增、删、改,都发生在这里。而当我们使用完了这个被修改过的容器之后,还可以使用docker commit和push指令,保存这个被修改过的可读写层,并上传到Docker Hub上,供其他人使用;而与此同时,原先的只读写层的内容则不会有任何变化。这,就是增量rootfs的好处。
AUFS
我现在有两个目录A和B,它们分别有两个文件:
1
2
3
4
5
6
7
8
|
$ tree
.
├── A
│ ├── a
│ └── x
└── B
├── b
└── x
|
然后,我使用联合挂载的方式,将这两个目录挂载到一个公共的目录C上:
1
2
|
$ mkdir C
$ mkdir -t aufs -o dirs=./A:./B none ./C
|
这时,我再查看目录C的内容,就能看到目录A和B下的文件被合并到了一起:
1
2
3
4
5
|
$ tree ./C
./C
├── a
├── b
└── x
|
可以看到,在这个合并后的目录C里,有a、b、x三个文件,并且x文件只有一份。这,就是"合并"的含义。此外,如果你在目录C里对a、b、x文件做修改,这些修改也会在对应的目录A、B中生效。
那么,在Docker项目中,又是如何使用这种Union File System的呢?
我的环境是Ubuntu 16.04和Docker CE 18.05, 这对组合默认使用的是AuFS这个联合文件系统的实现。你可以通过docker info命令,查看到这个信息(查看Storage Driver这项)。
AuFS的全程是Another UnionFS,后改名为Alternative UnionFS,再后来干脆改名叫做Advance UnionFS,从这些名字中你应该能看到这样两个事实:
- 它是对Linux原生UnionFS的重写和改进;
- 它的作者怨气好像很大。我猜是Linus Torvalds(Linux之父)一直不让AuFS进入Linxu内核主干的缘故,所以我们只能在Ubuntu和Debian这些发行版上使用它。
对于AuFS来说,它最关键的目录结构在/var/lib/docker路径上的diff目录:
1
|
/var/lib/docker/aufs/diff/<layer_id>
|
而这个目录的作用,我们不妨通过一个具体例子来看一下。
现在,我们启动一个容器,比如:
1
|
$ docker run -d ubuntu:latest sleep 3600
|
这个时候,Docker就会从Docker Hub上拉取一个Ubuntu镜像到本地。
这个所谓的"镜像”,实际上就是一个Ubuntu操作系统的rootfs,它的内容是Ubuntu操作系统的所有文件和目录。不过,与之前我们讲述的rootfs稍微不同的是,Docker镜像使用的rootfs,往往由多个"层"组成:
$ docker image inspect ubuntu:latest
...
"RootFS": {
"Type": "layers",
"Layers": [
"sha256:f49017d4d5ce9c0f544c...",
"sha256:8f2b771487e9d6354080...",
"sha256:ccd4d61916aaa2159429...",
"sha256:c01d74f99de40e097c73...",
"sha256:268a067217b5fe78e000..."
]
}
可以看到,这个Ubuntu镜像,实际上由5个层组成。这5个层就是5个增量rootfs,每一层都是Ubuntu操作系统文件和目录的一部分;而在使用镜像时,Docker会把这些增量联合挂载在一个统一的挂载点上(等价于前面例子里的"/C"目录)。
这个挂载点就是/var/lib/docker/aufs/mnt/, 比如:
/var/lib/docker/aufs/mnt/6e3be5d2ecccae7cc0fcfa2a2f5c89dc21ee30e166be823ceaeba15dce645b3e
不出意外的,这个目录里面正是一个完整的Ubuntu操作系统。
$ ls /var/lib/docker/aufs/mnt/6e3be5d2ecccae7cc0fcfa2a2f5c89dc21ee30e166be823ceaeba15dce645b3e
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
那么,前面提到的5个镜像层,又是如何被联合挂载成这样一个完整的Ubuntu文件系统的呢?
这个信息记录在AuFS的系统目录/sys/fs/aufs下面。
首先,通过查看AuFS的挂载信息,我们可以找到这个目录对应的AuFS的内部ID(也叫: si):
$ cat /proc/mounts| grep aufs
none /var/lib/docker/aufs/mnt/6e3be5d2ecccae7cc0fc... aufs rw,relatime,si=972c6d361e6b32ba,dio,dirperm1 0 0
即, si=972c6d361e6b32ba。
然后使用这个ID,你就可以在/sys/fs/aufs下查看被联合挂载在一起的各个层的信息:
$ cat /sys/fs/aufs/si_972c6d361e6b32ba/br[0-9]*
/var/lib/docker/aufs/diff/6e3be5d2ecccae7cc...=rw
/var/lib/docker/aufs/diff/6e3be5d2ecccae7cc...-init=ro+wh
/var/lib/docker/aufs/diff/32e8e20064858c0f2...=ro+wh
/var/lib/docker/aufs/diff/2b8858809bce62e62...=ro+wh
/var/lib/docker/aufs/diff/20707dce8efc0d267...=ro+wh
/var/lib/docker/aufs/diff/72b0744e06247c7d0...=ro+wh
/var/lib/docker/aufs/diff/a524a729adadedb90...=ro+wh
从这些信息里,我们可以看到,镜像的层都放置在/var/lib/docker/aufs/diff目录下,然后被联合挂载在/var/lib/docker/aufs/mnt里面。
而且,从这个结构可以看出来,这个容器的rootfs由如下图所示的三部分组成:
1
2
3
4
5
6
7
|
/var/lib/docker/aufs/diff/6e3be5d2ecccae7cc...=rw 可读写层
/var/lib/docker/aufs/diff/6e3be5d2ecccae7cc...-init=ro+wh Init层(ro+wh)
/var/lib/docker/aufs/diff/32e8e20064858c0f2...=ro+wh 只读层
/var/lib/docker/aufs/diff/2b8858809bce62e62...=ro+wh
/var/lib/docker/aufs/diff/20707dce8efc0d267...=ro+wh
/var/lib/docker/aufs/diff/72b0744e06247c7d0...=ro+wh
/var/lib/docker/aufs/diff/a524a729adadedb90...=ro+wh
|
第一部分,只读层。
它是这个容器的rootfs最下面的五层,对应的正是ubuntu:latest镜像的5层。可以看到,它们的挂载方式都是只读的(ro+wh, 即readonly+whiteout, 至于什么是whiteout, 我下面马上会讲到)。
这时,我们可以分别查看一下这些层的内容:
$ ls /var/lib/docker/aufs/diff/72b0744e06247c7d0...
etc sbin usr var
$ ls /var/lib/docker/aufs/diff/32e8e20064858c0f2...
run
$ ls /var/lib/docker/aufs/diff/a524a729adadedb900...
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
可以看到,这些层,都以增量的方式分别包含了Ubuntu操作系统的一部分。
第二部分,可读写层。
它是这个容器的rootfs最上面的一层(6e3be5d2ecccae7cc),它的挂载方式是: rw,
即read write。在没有写入文件之前,这个目录是空的。而一旦在容器里做了写操作,你修改产生的内容就会以增量的方式出现在这个层中。
可是,你有没有想到这样一个问题: 如果我现在要做的,是删除只读层里的一个文件呢?
为了实现这样的删除操作,AuFS会在可读写层创建一个whiteout文件,把只读层里的文件"遮挡"起来。
比如,你要删除只读层里一个名叫foo的文件,那么这个删除操作实际上是在可读写层创建了一个名叫.wh.foo的文件。这样,当这两个层被联合挂载之后,foo文件就会被.wh.foo文件"遮挡"起来,“消失"了。这个功能,就是"ro+wh"的挂载方式,即只读 + whiteout的含义。我喜欢把whiteout形象地翻译为: “白障”。
所以,最上面这个可读写层的作用,就是专门用来存放你修改rootfs后产生的增量,无论是增、删、改,都发生在这里。而当我们使用完了这个被修改过的容器之后,还可以使用docker commit和push指令,保存这个被修改过的可读写层,并上传到Docker Hub上,供其他人使用;而与此同时,原先的只读写层的内容则不会有任何变化。这,就是增量rootfs的好处。
第三部分,Init层。
它是一个以”-init"结尾的层,夹在只读层和读写层之间。Init层是Docker项目单独生成的一个内部层,专门用来存放/etc/hosts、/etc/resolv.conf等信息。
需要这样一层的原因是,这些文件本来属于只读的Ubuntu镜像的一部分,但是用户往往需要在启动容器时写入一些指定的值比如hostname,所以就需要在可读写层对它们进行修改。
可是,这些修改往往只对当前的容器有效,我们并不希望执行docker commit时,把这些信息连同可读写层一起提交掉。
所以,Docker做法是,在修改了这些文件之后,以一个单独的层挂载了出来。而用户执行docker commit只会提交可读写层,所以是不包含这些内容的。
最终,这7个层都被联合挂载到/var/lib/docker/aufs/mnt目录下,表现为一个完整的Ubuntu操作系统供容器使用。
实现volume挂载和镜像打包
上面介绍了如何使用overlay包装busybox,从而实现容器和镜像的分离。但是一旦容器退出,容器可写层的所有内容就会被删除。
那么,如果用户需要持久化容器里的部分数据该怎么办呢?volume就是用来解决这个问题的。
目标: 将宿主机的目录作为数据卷挂载到容器中,并且在容器退出后,数据卷中的内容仍然能够保存在宿主机上。
思路:修改上面介绍的overlay创建容器文件系统的过程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
|
package main
import (
"os/exec"
"strings"
"syscall"
"os"
"path/filepath"
"log"
"fmt"
"flag"
"io/ioutil"
)
var (
mntURL = "/root/mnt"
rootURL= "/root/"
)
func NewPipe() (*os.File, *os.File, error) {
read, write, err := os.Pipe()
if err != nil {
return nil, nil, err
}
return read, write, nil
}
func readUserCommand() []string {
// uintptr(3)就是指index为3的文件描述符,也就是传递进来的管道的一端
// 第二参数表示文件的名字
pipe := os.NewFile(uintptr(3), "pipe")
msg, err := ioutil.ReadAll(pipe)
if err != nil {
println("init read pipe error: ", err.Error())
return nil
}
msgStr := string(msg)
return strings.Split(msgStr, " ")
}
func sendInitCommand(comArray []string, writePipe *os.File) {
command := strings.Join(comArray, " ")
println("command all is ", command)
writePipe.WriteString(command)
writePipe.Close()
}
func main() {
// 由于使用了管道,所以在调用init子命令的时候,是没有参数的
// 于是这里的3要改为2
if len(os.Args) < 2 {
println("parameter must greater than 1")
os.Exit(0)
}
cl := flag.NewFlagSet(os.Args[1], flag.ExitOnError)
switch os.Args[1] {
case "run":
if len(os.Args) < 3 {
println("Missing command")
os.Exit(-1)
}
// 设置option
var tty bool
// 3-1: 添加-v标签
var m, cpushare, cpuset, v string
cl.BoolVar(&tty, "it", false, "enable tty")
cl.StringVar(&m, "m", "", "memory limit")
cl.StringVar(&cpushare, "cpushare", "", "cpushare limit")
cl.StringVar(&cpuset, "cpuset", "", "cpuset limit")
cl.StringVar(&v, "v", "", "volume")
cl.Parse(os.Args[2:])
if len(cl.Args()) < 1 {
println("Missing container command")
os.Exit(-1)
}
println("run..............")
// 1.改动
readPipe, writePipe, err := NewPipe()
if err != nil {
println("New pipe error: ", err.Error())
os.Exit(-1)
}
cmd := exec.Command("/proc/self/exe", "init")
cmd.SysProcAttr = &syscall.SysProcAttr {
Cloneflags: syscall.CLONE_NEWUTS|syscall.CLONE_NEWIPC|syscall.CLONE_NEWPID|syscall.CLONE_NEWNS|syscall.CLONE_NEWNET|syscall.CLONE_NEWIPC,
}
println("tty", tty)
if tty {
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
}
// 1.注意,改动在这里,在这个地方传入管道文件读取端的句柄
// 管道是一个文件类型,肯定不能通过字符参数的方式进行传递,因此使用了command的cmd.ExtraFiles属性
// 这个属性的意思是会外带着这个文件句柄去创建子进程,可以使用命令`ll /proc/self/fd`来查看当前进程带着的所有文件描述符
// 由于,每个进程都会有三个默认的文件描述符,标准输入、标准输出、标准错误,所以这个外带的文件句柄就成了第四个。
cmd.ExtraFiles = []*os.File{readPipe}
// 3. 改动
// 在启动父进程之前,设置它的当前路径
// 这个路径非常关键,后面的pivotRoot操作,会使用到这个当前路径
NewWorkSpace(rootURL, mntURL, v)
cmd.Dir = mntURL
// 运行父进程cmd
if err := cmd.Start(); err != nil {
log.Fatal(err)
}
// 2.注意,改动在这里,在这个地方添加对资源的限制
// use mydocker-cgroup as cgroup name
// 创建cgroup manager,并通过调用set和apply设置资源限制并使限制在容器上生效。
cgroupManager := NewCgroupManager("mydocker-cgroup")
defer cgroupManager.Destroy()
// 设置资源限制
res := &ResourceConfig{
MemoryLimit: m,
CpuSet: cpuset,
CpuShare: cpushare,
}
cgroupManager.Set(res)
// 将容器进程加入到每个cgroup中
cgroupManager.Apply(cmd.Process.Pid)
// 1.发送用户命令
sendInitCommand(cl.Args(), writePipe)
cmd.Wait()
// 3. 改动:
// docker会在删除容器的时候,把容器对应的Write Layer和Container-init Layer删除,而保留镜像所有的内容
// 在这里,我们简化为只删除Write Layer (Container-init的处理,非常复杂)
DeleteWorkSpace(rootURL, mntURL, v)
os.Exit(-1)
case "init":
// 1.获取用户命令
cmdArray := readUserCommand()
if cmdArray == nil || len(cmdArray) == 0 {
println("Run container get user command error, cmdArray is nil")
os.Exit(-1)
}
println("command is ", strings.Join(cmdArray, " "))
// 如果你的机器的根目录的挂载类型是shared,那必须先重新挂载根目录mount --make-rprivate
if err := syscall.Mount("","/","",syscall.MS_PRIVATE|syscall.MS_REC, ""); err != nil {
log.Fatal("make parent mount private error: %v", err)
}
// MS_NOEXEC: 在文件系统中不允许运行其他程序
// MS_NOSUID: 在本系统中运行程序的时候,不允许set-user-ID或set-group-ID
// MS_NODEV: 这个参数是自从Linux2.4以来,所有mount的系统都会默认设定的参数
defaultMountFlags := syscall.MS_NOEXEC | syscall.MS_NOSUID | syscall.MS_NODEV
syscall.Mount("proc", "/proc", "proc", uintptr(defaultMountFlags), "")
// 3. 改动,调用PivotRoot方法,将当前目录设置为容器内的根目录(所以,在执行程序是,需要先cd到busybox的rootfs目录下)
// 注意,在执行之前,需要给宿主机的PATH环境变量添加/bin路径,因为容器会使用宿主机的PATH环境变量的值。
path_v := os.Getenv("PATH")
if !strings.HasPrefix(path_v, "/bin") && !strings.Contains(path_v, ":/bin") {
path_v = path_v + ":/bin"
os.Setenv("PATH", path_v)
}
println("PATH environment variable is ", path_v)
setUpMount()
// 改动,调用exec.LookPath, 可以在系统的PATH里面寻找命令的绝对路径
path, err := exec.LookPath(cmdArray[0])
if err != nil {
println("Exec loop path error : ", err.Error())
os.Exit(-1)
}
println("Find path: ", path)
if err := syscall.Exec(path, cmdArray[0:], os.Environ()); err != nil {
println(err.Error())
}
case "commit":
// 3-2: 添加镜像commit的功能(把运行状态容器的内容存储成镜像保存下来)
if len(os.Args) < 3 {
println("Missing container name")
os.Exit(-1)
}
imageName := os.Args[2]
commitContainer(imageName)
default:
println("Usage: ./test run|init")
os.Exit(2)
}
}
func commitContainer(imageName string) {
mntURL := "/root/mnt"
imageTar := "/root/" + imageName + ".tar"
fmt.Printf("%s", imageTar)
if _, err := exec.Command("tar", "-czf", imageTar, "-C", mntURL, ".").CombinedOutput(); err != nil {
fmt.Printf("Tar folder %s error %v\n", mntURL, err)
}
}
// 在init子命令中,使用pivotRoot进行一系列的mount操作
func setUpMount() {
// 获取当前路径
pwd, err := os.Getwd()
if err != nil {
println("Get current location error %v", err)
return
}
println("Current location is %s", pwd)
pivotRoot(pwd)
// mount proc
defaultMountFlags := syscall.MS_NOEXEC | syscall.MS_NOSUID | syscall.MS_NODEV
syscall.Mount("proc", "/proc", "proc", uintptr(defaultMountFlags), "")
// tmpfs是一种基于内存的文件系统,可以使用RAM或swap分区来存储。
syscall.Mount("tmpfs", "/dev", "tmpfs", syscall.MS_NOSUID|syscall.MS_STRICTATIME, "mode=755")
}
// 注意,新增的代码(实现rootfs)
func pivotRoot(root string) error {
// 为了使当前root的老root和新root不在同一个文件系统下,我们把root重新mount了一次
// bind mount是把相同的内容换了一个挂载点的挂载方法
if err := syscall.Mount(root, root, "bind", syscall.MS_BIND|syscall.MS_REC, ""); err != nil {
return fmt.Errorf("Mount rootfs to itself error: %v", err)
}
// 创建rootfs/.pivot_root 存储 old_root
pivotDir := filepath.Join(root, ".pivot_root")
if err := os.Mkdir(pivotDir, 0777); err != nil {
return err
}
// pivot_root到新的rootfs,老的old_root现在挂载在rootfs/.pivot_root上
// 挂载点目前依然可以在mount命令中看到
if err := syscall.PivotRoot(root, pivotDir); err != nil {
return fmt.Errorf("pivot_root %v", err)
}
// 修改当前的工作目录到根目录
if err := syscall.Chdir("/"); err != nil {
return fmt.Errorf("chdir / %v", err)
}
pivotDir = filepath.Join("/", ".pivot_root")
// umount rootfs/.pivot_root
if err := syscall.Unmount(pivotDir, syscall.MNT_DETACH); err != nil {
return fmt.Errorf("unmount pivot_root dir %v", err)
}
// 删除临时文件夹
return os.Remove(pivotDir)
}
// 使用overlay包装busybox(rootfs)
//Create a overlay filesystem as container root workspace
func NewWorkSpace(rootURL string, mntURL string, volume string) {
CreateReadOnlyLayer(rootURL)
CreateWriteLayer(rootURL)
CreateMountPoint(rootURL, mntURL)
// 3-1改动
// 根据volume判断是否执行挂载数据卷操作
if volume != "" {
volumeURLs := volumeUrlExtract(volume)
length := len(volumeURLs)
if length == 2 && volumeURLs[0] != "" && volumeURLs[1] != "" {
MountVolume(rootURL, mntURL, volumeURLs)
fmt.Printf("%q\n", volumeURLs)
}else {
println("Volume parameter input is not correct")
}
}
}
// 3-1改动
// 解析volume字符串
func volumeUrlExtract(volume string) ([]string) {
var volumeURLs []string
volumeURLs = strings.Split(volume, ":")
return volumeURLs
}
// 3-1改动
// 挂载数据卷的过程
func MountVolume(rootURL string, mntURL string, volumeURLs []string) {
// 创建宿主机文件目录
parentUrl := volumeURLs[0]
if err := os.Mkdir(parentUrl, 0777); err != nil {
fmt.Printf("Mkdir parent dir %s error. %v\n", parentUrl, err)
}
// 在容器文件系统里创建挂载点
containerUrl := volumeURLs[1]
containerVolumeURL := mntURL + containerUrl
if err := os.Mkdir(containerVolumeURL, 0777); err != nil {
fmt.Printf("Mkdir container dir %s error. %v\n", containerVolumeURL, err)
}
// 把宿主机文件目录挂载到容器挂载点
workLayer := rootURL+"workLayer"
cmd := exec.Command("mount", "-t", "overlay", "-o", fmt.Sprintf("lowerdir=%s,upperdir=%s,workdir=%s", parentUrl, parentUrl, workLayer), "none", containerVolumeURL)
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
fmt.Printf("Mount volume failed. %v\n", err)
}
}
func CreateReadOnlyLayer(rootURL string) {
busyboxURL := rootURL + "busybox/"
busyboxTarURL := rootURL + "busybox.tar"
exist, err := PathExists(busyboxURL)
if err != nil {
fmt.Printf("Fail to judge whether dir %s exists. %v\n", busyboxURL, err)
}
if exist == false {
if err := os.Mkdir(busyboxURL, 0777); err != nil {
fmt.Printf("Mkdir dir %s error. %v\n", busyboxURL, err)
}
if _, err := exec.Command("tar", "-xvf", busyboxTarURL, "-C", busyboxURL).CombinedOutput(); err != nil {
fmt.Printf("Untar dir %s error %v\n", busyboxURL, err)
}
}
}
func CreateWriteLayer(rootURL string) {
writeURL := rootURL + "writeLayer/"
if err := os.Mkdir(writeURL, 0777); err != nil {
fmt.Printf("Mkdir dir %s error. %v\n", writeURL, err)
}
}
func CreateMountPoint(rootURL string, mntURL string) {
if err := os.Mkdir(mntURL, 0777); err != nil {
fmt.Printf("Mkdir dir %s error. %v\n", mntURL, err)
}
workLayer := rootURL+"workLayer"
if err := os.Mkdir(workLayer, 0777); err != nil {
fmt.Printf("Mkdir dir %s error. %v\n", mntURL, err)
}
// 注意,在这里需要使用到overlay文件系统
cmd := exec.Command("mount", "-t", "overlay", "-o", fmt.Sprintf("lowerdir=%s,upperdir=%s,workdir=%s", rootURL+"busybox/", rootURL+"writeLayer", workLayer), "none", mntURL)
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
println(err.Error())
}
}
//Delete the overlay filesystem while container exit
func DeleteWorkSpace(rootURL string, mntURL string, volume string){
// 3-1 添加文件挂载的功能
if volume != "" {
volumeURLs := volumeUrlExtract(volume)
length := len(volumeURLs)
if length == 2 && volumeURLs[0] != "" && volumeURLs[1] != "" {
DeleteMountPointWithVolume(rootURL, mntURL, volumeURLs)
}else {
DeleteMountPoint(rootURL, mntURL)
}
} else {
DeleteMountPoint(rootURL, mntURL)
}
DeleteWriteLayer(rootURL)
}
// 3-1
func DeleteMountPointWithVolume(rootURL string, mntURL string, volumeURLs []string){
// 3-1 卸载容器里volume挂载点的文件系统
containerUrl := mntURL + volumeURLs[1]
cmd := exec.Command("umount", containerUrl)
cmd.Stdout=os.Stdout
cmd.Stderr=os.Stderr
if err := cmd.Run(); err != nil {
fmt.Printf("Umount volume failed. %v\n",err)
}
cmd = exec.Command("umount", mntURL)
cmd.Stdout=os.Stdout
cmd.Stderr=os.Stderr
if err := cmd.Run(); err != nil {
fmt.Printf("Umount mountpoint failed. %v\n",err)
}
if err := os.RemoveAll(mntURL); err != nil {
fmt.Printf("Remove mountpoint dir %s error %v\n", mntURL, err)
}
}
func DeleteMountPoint(rootURL string, mntURL string){
cmd := exec.Command("umount", mntURL)
cmd.Stdout=os.Stdout
cmd.Stderr=os.Stderr
if err := cmd.Run(); err != nil {
println(err)
}
if err := os.RemoveAll(mntURL); err != nil {
fmt.Printf("Remove dir %s error %v\n", mntURL, err)
}
}
func DeleteWriteLayer(rootURL string) {
writeURL := rootURL + "writeLayer/"
if err := os.RemoveAll(writeURL); err != nil {
fmt.Printf("Remove dir %s error %v\n", writeURL, err)
}
workURL := rootURL + "workLayer/"
if err := os.RemoveAll(workURL); err != nil {
fmt.Printf("Remove dir %s error %v\n", workURL, err)
}
}
func PathExists(path string) (bool, error) {
_, err := os.Stat(path)
if err == nil {
return true, nil
}
if os.IsNotExist(err) {
return false, nil
}
return false, err
}
|
本文发表于 0001-01-01,最后修改于 0001-01-01。
本站永久域名「 jiavvc.top
」,也可搜索「 后浪笔记一零二四 」找到我。
上一篇 «
下一篇 »

